Learning Goals¶
By the end of this tutorial, you will:
Learn where Euclid Q1 data are stored in the cloud.
Retrieve an image cutout from the cloud.
Retrieve a spectrum from the cloud.
1. Introduction¶
Euclid launched in July 2023 as a European Space Agency (ESA) mission with involvement by NASA. The primary science goals of Euclid are to better understand the composition and evolution of the dark Universe. The Euclid mission is providing space-based imaging and spectroscopy as well as supporting ground-based imaging to achieve these primary goals. These data will be archived by multiple global repositories, including IRSA, where they will support transformational work in many areas of astrophysics.
Euclid Quick Release 1 (Q1) consists of consists of ~30 TB of imaging, spectroscopy, and catalogs covering four non-contiguous fields: Euclid Deep Field North (22.9 sq deg), Euclid Deep Field Fornax (12.1 sq deg), Euclid Deep Field South (28.1 sq deg), and LDN1641.
IRSA maintains copies of the Euclid Q1 data products both on premises at IPAC and on the cloud via Amazon Web Services (AWS). This notebook provides an introduction to accessing Euclid Q1 data from the cloud. If you have questions, please contact the IRSA helpdesk.
2. Imports¶
s3fsfor browsing S3 bucketsastropyfor handling coordinates, units, FITS I/O, tables, images, etc.astroquery>=0.4.10for querying Euclid data products from IRSAmatplotlibfor visualizationjsonfor decoding JSON strings
# Uncomment the next line to install dependencies if needed.
# !pip install s3fs astropy 'astroquery>=0.4.10' matplotlibimport s3fs
from astropy.coordinates import SkyCoord
import astropy.units as u
from astropy.visualization import ImageNormalize, PercentileInterval, AsinhStretch
from astropy.io import fits
from astropy.nddata import Cutout2D
from astropy.wcs import WCS
from astropy.table import Table
from astroquery.ipac.irsa import Irsa
from matplotlib import pyplot as plt
import json3. Browse Euclid Q1 cloud-hosted data¶
BUCKET_NAME = 'nasa-irsa-euclid-q1's3fs provides a filesystem-like python interface for AWS S3 buckets. First we create a s3 client:
s3 = s3fs.S3FileSystem(anon=True)Then we list the q1 directory that contains Euclid Q1 data products:
s3.ls(f'{BUCKET_NAME}/q1')['nasa-irsa-euclid-q1/q1/MER',
'nasa-irsa-euclid-q1/q1/MER_SEG',
'nasa-irsa-euclid-q1/q1/NIR',
'nasa-irsa-euclid-q1/q1/RAW',
'nasa-irsa-euclid-q1/q1/SIR',
'nasa-irsa-euclid-q1/q1/VIS',
'nasa-irsa-euclid-q1/q1/VMPZ',
'nasa-irsa-euclid-q1/q1/catalogs',
'nasa-irsa-euclid-q1/q1/euclid_q1-awscli_cp.script',
'nasa-irsa-euclid-q1/q1/euclid_q1-wget.script']Let’s navigate to MER images (available as FITS files):
s3.ls(f'{BUCKET_NAME}/q1/MER')[:10] # ls only top 10 to limit the long output['nasa-irsa-euclid-q1/q1/MER/102018211',
'nasa-irsa-euclid-q1/q1/MER/102018212',
'nasa-irsa-euclid-q1/q1/MER/102018213',
'nasa-irsa-euclid-q1/q1/MER/102018664',
'nasa-irsa-euclid-q1/q1/MER/102018665',
'nasa-irsa-euclid-q1/q1/MER/102018666',
'nasa-irsa-euclid-q1/q1/MER/102018667',
'nasa-irsa-euclid-q1/q1/MER/102018668',
'nasa-irsa-euclid-q1/q1/MER/102018669',
'nasa-irsa-euclid-q1/q1/MER/102018670']s3.ls(f'{BUCKET_NAME}/q1/MER/102018211') # pick any tile ID from above['nasa-irsa-euclid-q1/q1/MER/102018211/DECAM',
'nasa-irsa-euclid-q1/q1/MER/102018211/NISP',
'nasa-irsa-euclid-q1/q1/MER/102018211/VIS']s3.ls(f'{BUCKET_NAME}/q1/MER/102018211/VIS') # pick any instrument from above['nasa-irsa-euclid-q1/q1/MER/102018211/VIS/EUC_MER_BGMOD-VIS_TILE102018211-4CD9D_20241018T142710.276652Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102018211/VIS/EUC_MER_BGSUB-MOSAIC-VIS_TILE102018211-ACBD03_20241018T142710.276838Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102018211/VIS/EUC_MER_CATALOG-PSF-VIS_TILE102018211-55C665_20241018T204235.689380Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102018211/VIS/EUC_MER_GRID-PSF-VIS_TILE102018211-9A5C08_20241018T142525.109781Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102018211/VIS/EUC_MER_MOSAIC-VIS-FLAG_TILE102018211-40A124_20241018T142525.109767Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102018211/VIS/EUC_MER_MOSAIC-VIS-RMS_TILE102018211-B3070B_20241018T142525.109753Z_00.00.fits']As per “Browsable Directories” section in user guide, we need MER/{tile_id}/{instrument}/EUC_MER_BGSUB-MOSAIC*.fits for displaying background-subtracted mosiac images. But these images are stored under TILE IDs so first we need to find TILE ID for a coordinate search we are interested in. We will use astroquery (in next section) to retrieve FITS file paths for our coordinates by doing spatial search.
4. Do a spatial search for MER mosaics¶
Pick a target and search radius:
target_name = 'TYC 4429-1677-1'
coord = SkyCoord.from_name(target_name)
search_radius = 10 * u.arcsecAs per “Data Products Overview” in user guide and above table, we identify that MER Mosiacs are available as the following collection:
img_collection = 'euclid_DpdMerBksMosaic'Now query this collection for our target’s coordinates and search radius:
img_tbl = Irsa.query_sia(pos=(coord, search_radius), collection=img_collection)
img_tblLet’s narrow it down to the images with science dataproduct subtype and Euclid facility:
euclid_sci_img_tbl = img_tbl[[row['facility_name']=='Euclid'
and row['dataproduct_subtype']=='science'
for row in img_tbl]]
euclid_sci_img_tblWe can see there’s a cloud_access column that gives us the location info of the image files we are interested in. So let’s extract the S3 bucket file path from it:
def get_s3_fpath(cloud_access):
cloud_info = json.loads(cloud_access) # converts str to dict
bucket_name = cloud_info['aws']['bucket_name']
key = cloud_info['aws']['key']
return f'{bucket_name}/{key}'[get_s3_fpath(row['cloud_access']) for row in euclid_sci_img_tbl]['nasa-irsa-euclid-q1/q1/MER/102160339/NISP/EUC_MER_BGSUB-MOSAIC-NIR-J_TILE102160339-B6EC5E_20241024T230609.320185Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102160339/NISP/EUC_MER_BGSUB-MOSAIC-NIR-H_TILE102160339-539320_20241024T230405.104628Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102160339/NISP/EUC_MER_BGSUB-MOSAIC-NIR-Y_TILE102160339-3A9BC7_20241024T231706.521789Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/MER/102160339/VIS/EUC_MER_BGSUB-MOSAIC-VIS_TILE102160339-ADF1FF_20241025T022657.824470Z_00.00.fits']Let’s also extract filter names to use when displaying the images:
def get_filter_name(instrument, bandpass):
return f'{instrument}_{bandpass}' if instrument!=bandpass else instrument[get_filter_name(row['instrument_name'], row['energy_bandpassname']) for row in euclid_sci_img_tbl]['NISP_J', 'NISP_H', 'NISP_Y', 'VIS']5. Efficiently retrieve mosaic cutouts¶
These image files are very big (~1.4GB), so we use astropy’s lazy-loading capability of FITS for better performance. (See Obtaining subsets from cloud-hosted FITS files.)
cutout_size = 1 * u.arcmincutouts = []
filters = []
for row in euclid_sci_img_tbl:
s3_fpath = get_s3_fpath(row['cloud_access'])
filter_name = get_filter_name(row['instrument_name'], row['energy_bandpassname'])
with fits.open(f's3://{s3_fpath}', fsspec_kwargs={"anon": True}) as hdul:
print(f'Retrieving cutout for {filter_name} ...')
cutout = Cutout2D(hdul[0].section,
position=coord,
size=cutout_size,
wcs=WCS(hdul[0].header))
cutouts.append(cutout)
filters.append(filter_name)Retrieving cutout for NISP_J ...
Retrieving cutout for NISP_H ...
Retrieving cutout for NISP_Y ...
Retrieving cutout for VIS ...
fig, axes = plt.subplots(2, 2, figsize=(4 * 2, 4 * 2), subplot_kw={'projection': cutouts[0].wcs})
for idx, ax in enumerate(axes.flat):
norm = ImageNormalize(cutouts[idx].data, interval=PercentileInterval(99), stretch=AsinhStretch())
ax.imshow(cutouts[idx].data, cmap='gray', origin='lower', norm=norm)
ax.set_xlabel('RA')
ax.set_ylabel('Dec')
ax.text(0.95, 0.05, filters[idx], color='white', fontsize=14, transform=ax.transAxes, va='bottom', ha='right')
plt.tight_layout()
6. Find the MER catalog for a given tile¶
Let’s navigate to MER catalog in the Euclid Q1 bucket:
s3.ls(f'{BUCKET_NAME}/q1/catalogs')['nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG',
'nasa-irsa-euclid-q1/q1/catalogs/NIR_CAL_CATALOG',
'nasa-irsa-euclid-q1/q1/catalogs/PHZ_PF_OUTPUT_CATALOG',
'nasa-irsa-euclid-q1/q1/catalogs/PHZ_PF_OUTPUT_FOR_L3',
'nasa-irsa-euclid-q1/q1/catalogs/SPE_PF_OUTPUT_CATALOG',
'nasa-irsa-euclid-q1/q1/catalogs/VIS_CAL_CATALOG',
'nasa-irsa-euclid-q1/q1/catalogs/euclid_q1-catalogs.md5']s3.ls(f'{BUCKET_NAME}/q1/catalogs/MER_FINAL_CATALOG')[:10] # ls only top 10 to limit the long output['nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018211',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018212',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018213',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018664',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018665',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018666',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018667',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018668',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018669',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102018670']mer_tile_id = 102160339 # from the image paths for the target we picked
s3.ls(f'{BUCKET_NAME}/q1/catalogs/MER_FINAL_CATALOG/{mer_tile_id}')['nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102160339/EUC_MER_FINAL-CAT_TILE102160339-52AA9D_20241026T145149.163369Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102160339/EUC_MER_FINAL-CUTOUTS-CAT_TILE102160339-7449E7_20241026T034412.641243Z_00.00.fits',
'nasa-irsa-euclid-q1/q1/catalogs/MER_FINAL_CATALOG/102160339/EUC_MER_FINAL-MORPH-CAT_TILE102160339-52C86_20241026T145146.071857Z_00.00.fits']As per “Browsable Directiories” section in user guide, we can use catalogs/MER_FINAL_CATALOG/{tile_id}/EUC_MER_FINAL-CAT*.fits for listing the objects catalogued. We can read the identified FITS file as table and do filtering on ra, dec columns to find object ID(s) only for the target we picked. But it will be an expensive operation so we will instead use astroquery (in next section) to do a spatial search in the MER catalog provided by IRSA.
7. Find the MER Object ID for our target¶
First, list the Euclid catalogs provided by IRSA:
catalogs = Irsa.list_catalogs(full=True, filter='euclid')
catalogsFrom this table, we can extract the MER catalog name. We also see several other interesting catalogs, let’s also extract spectral file association catalog for retrieving spectra later.
euclid_mer_catalog = 'euclid_q1_mer_catalogue'
euclid_spec_association_catalog = 'euclid.objectid_spectrafile_association_q1'Now, we do a region search within a cone of 5 arcsec around our target to pinpoint its object ID in Euclid catalog:
search_radius = 5 * u.arcsec
mer_catalog_tbl = Irsa.query_region(coordinates=coord, spatial='Cone',
catalog=euclid_mer_catalog, radius=search_radius)
mer_catalog_tblobject_id = int(mer_catalog_tbl['object_id'][0])
object_id27311734286820780458. Find the spectrum of an object in the MER catalog¶
Using the object ID(s) we extracted above, we can narrow down the spectral file association catalog to identify spectra file path(s). So we do the following TAP search:
adql_query = f"SELECT * FROM {euclid_spec_association_catalog} \
WHERE objectid = {object_id}"
spec_association_tbl = Irsa.query_tap(adql_query).to_table()
spec_association_tblIn above table, we can see that the 'path' column gives us a url that can be used to call an IRSA service to get the spectrum of our object as SpectrumDM VOTable. We can map it to an S3 bucket key to retrieve a spectra file from the cloud. This is a very big FITS spectra file with multiple extensions where each extension contains spectrum of one object. The 'hdu' column gives us the extension number for our object. So let’s extract both of these.
spec_fpath_key = spec_association_tbl['path'][0].replace('api/spectrumdm/convert/euclid/', '').split('?')[0]
spec_fpath_key'q1/SIR/102160339/EUC_SIR_W-COMBSPEC_102160339_2024-11-05T16:26:34.614296Z.fits'object_hdu_idx = int(spec_association_tbl['hdu'][0])
object_hdu_idx1644Again, we use astropy’s lazy-loading capability of FITS to only retrieve the spectrum table of our object from the S3 bucket.
with fits.open(f's3://{BUCKET_NAME}/{spec_fpath_key}', fsspec_kwargs={'anon': True}) as hdul:
spec_hdu = hdul[object_hdu_idx]
spec_tbl = Table.read(spec_hdu)
spec_header = spec_hdu.headerWARNING: UnitsWarning: 'Number' did not parse as fits unit: At col 0, Unit 'Number' not supported by the FITS standard. If this is meant to be a custom unit, define it with 'u.def_unit'. To have it recognized inside a file reader or other code, enable it with 'u.add_enabled_units'. For details, see https://docs.astropy.org/en/latest/units/combining_and_defining.html [astropy.units.core]
WARNING: UnitsWarning: 'Number' did not parse as fits unit: At col 0, Unit 'Number' not supported by the FITS standard. If this is meant to be a custom unit, define it with 'u.def_unit'. To have it recognized inside a file reader or other code, enable it with 'u.add_enabled_units'. For details, see https://docs.astropy.org/en/latest/units/combining_and_defining.html [astropy.units.core]
WARNING: UnitsWarning: 'Number' did not parse as fits unit: At col 0, Unit 'Number' not supported by the FITS standard. If this is meant to be a custom unit, define it with 'u.def_unit'. To have it recognized inside a file reader or other code, enable it with 'u.add_enabled_units'. For details, see https://docs.astropy.org/en/latest/units/combining_and_defining.html [astropy.units.core]
spec_tbl# The signal needs to be multiplied by the scale factor in the header.
plt.plot(spec_tbl['WAVELENGTH'], spec_header['FSCALE'] * spec_tbl['SIGNAL'])
plt.xlabel(spec_tbl['WAVELENGTH'].unit.to_string('latex_inline'))
plt.ylabel(spec_tbl['SIGNAL'].unit.to_string('latex_inline'))
plt.title(f'Spectrum of Target: {target_name}\n(Euclid Object ID: {object_id})');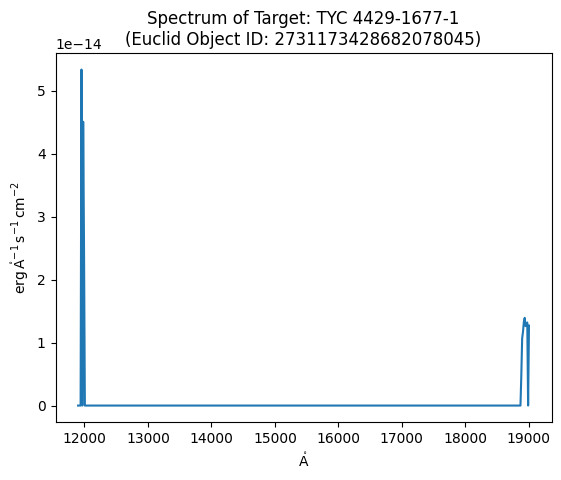
About this Notebook¶
Updated: 2025-09-23
Contact: the IRSA Helpdesk with questions or reporting problems.