Euclid Q1: 1D spectra#
Learning Goals#
By the end of this tutorial, you will:
Understand the basic characteristics of Euclid Q1 SIR 1D spectra.
What columns are available in the MER catalog.
How to query with ADQL in the MER catalog.
How to make a simple color-magnitude diagram with the data.
Introduction#
Euclid launched in July 2023 as a European Space Agency (ESA) mission with involvement by NASA. The primary science goals of Euclid are to better understand the composition and evolution of the dark Universe. The Euclid mission is providing space-based imaging and spectroscopy as well as supporting ground-based imaging to achieve these primary goals. These data will be archived by multiple global repositories, including IRSA, where they will support transformational work in many areas of astrophysics.
Euclid Quick Release 1 (Q1) consists of consists of ~30 TB of imaging, spectroscopy, and catalogs covering four non-contiguous fields: Euclid Deep Field North (22.9 sq deg), Euclid Deep Field Fornax (12.1 sq deg), Euclid Deep Field South (28.1 sq deg), and LDN1641.
Among the data products included in the Q1 release are the 1D spectra created by the SIR Processing Function. This notebook provides an introduction to these SIR 1D spectra. If you have questions about it, please contact the IRSA helpdesk.
Imports#
Important
We rely on astroquery features that have been recently added, so please make sure you have version v0.4.10 or newer installed.
# Uncomment the next line to install dependencies if needed
# !pip install matplotlib astropy 'astroquery>=0.4.10'
import urllib
import numpy as np
import matplotlib.pyplot as plt
from astropy.io import fits
from astropy.table import QTable
from astropy import units as u
from astropy.visualization import quantity_support
from astroquery.ipac.irsa import Irsa
1. Search for the spectrum of a specific galaxy#
First, explore what Euclid catalogs are available. Note that we need to use the object ID for our targets to be able to download their spectrum.
Search for all tables in IRSA labeled as “euclid”.
Irsa.list_catalogs(filter='euclid')
{'euclid_q1_mer_catalogue': 'Euclid Q1 MER Catalog',
'euclid_q1_mer_morphology': 'Euclid Q1 MER Morphology',
'euclid_q1_mer_cutouts': 'Euclid Q1 MER Cutouts',
'euclid_q1_phz_photo_z': 'Euclid Q1 PHZ Photo-z Catalog',
'euclid_q1_phz_star_sed': 'Euclid Q1 PHZ Star SED Catalog',
'euclid_q1_phz_galaxy_sed': 'Euclid Q1 PHZ Galaxy SED Catalog',
'euclid_q1_phz_classification': 'Euclid Q1 PHZ Classification Catalog',
'euclid_q1_phz_qso_physical_parameters': 'Euclid Q1 PHZ QSO Physical Parameters Catalog',
'euclid_q1_phz_nir_physical_parameters': 'Euclid Q1 PHZ NIR Physical Parameters Catalog',
'euclid_q1_phz_star_template': 'Euclid Q1 PHZ Star Template Catalog',
'euclid_q1_spectro_zcatalog_spe_quality': 'Euclid Q1 SPE Redshift Catalog - Quality',
'euclid_q1_spectro_zcatalog_spe_classification': 'Euclid Q1 SPE Redshift Catalog - Classification',
'euclid_q1_spectro_zcatalog_spe_galaxy_candidates': 'Euclid Q1 SPE Redshift Catalog - Galaxy Candidates',
'euclid_q1_spectro_zcatalog_spe_star_candidates': 'Euclid Q1 SPE Redshift Catalog - Star Candidates',
'euclid_q1_spectro_zcatalog_spe_qso_candidates': 'Euclid Q1 SPE Redshift Catalog - QSO Candidates',
'euclid_q1_spe_lines_line_features': 'Euclid Q1 SPE Lines Catalog - Spectral Lines',
'euclid_q1_spe_lines_continuum_features': 'Euclid Q1 SPE Lines Catalog - Continuum Features',
'euclid_q1_spe_lines_atomic_indices': 'Euclid Q1 SPE Lines Catalog - Atomic Indices',
'euclid_q1_spe_lines_molecular_indices': 'Euclid Q1 SPE Lines Catalog - Molecular Indices',
'euclid_q1_spectro_model_catalog_spe_lines_catalog': 'Euclid Q1 SPE Models Catalog - Lines',
'euclid_q1_spectro_model_catalog_spe_star_models': 'Euclid Q1 SPE Star Models Catalog',
'euclid.tileid_association_q1': 'Euclid Q1 TILEID to Observation ID Association Table',
'euclid.objectid_spectrafile_association_q1': 'Euclid Q1 Object ID to Spectral File Association Table',
'euclid.observation_euclid_q1': 'Euclid Q1 CAOM Observation Table',
'euclid.plane_euclid_q1': 'Euclid Q1 CAOM Plane Table',
'euclid.artifact_euclid_q1': 'Euclid Q1 CAOM Artifact Table'}
table_1dspectra = 'euclid.objectid_spectrafile_association_q1'
2. Search for the spectrum of a specific galaxy in the 1D spectra table#
obj_id = 2689918641685825137
We will use TAP and an ASQL query to find the spectral data for our galaxy. (ADQL is the IVOA Astronomical Data Query Language and is based on SQL.)
adql_object = f"SELECT * FROM {table_1dspectra} WHERE objectid = {obj_id}"
# Pull the data on this particular galaxy
result = Irsa.query_tap(adql_object).to_table()
Pull out the file name from the result table:
file_uri = urllib.parse.urljoin(Irsa.tap_url, result['uri'][0])
file_uri
'https://irsa.ipac.caltech.edu/ibe/data/euclid/q1/SIR/102160608/EUC_SIR_W-COMBSPEC_102160608_2024-11-05T16:42:00.741819Z.fits'
3. Read in the spectrum for only our specific object#
Currently IRSA has the spectra stored in very large files containing multiple (14220) extensions with spectra of many targets within one tile. You can choose to read in the big file below to see what it looks like (takes a few mins to load) or skip this step and just read in the specific extension we want for the 1D spectra (recommended).
# hdul = fits.open(file_uri)
# hdul.info()
Open the large FITS file without loading it entirely into memory, pulling out just the extension we want for the 1D spectra of our object
with fits.open(file_uri) as hdul:
spectrum = QTable.read(hdul[result['hdu'][0]], format='fits')
spec_header = hdul[result['hdu'][0]].header
WARNING: UnitsWarning: 'Number' did not parse as fits unit: At col 0, Unit 'Number' not supported by the FITS standard. If this is meant to be a custom unit, define it with 'u.def_unit'. To have it recognized inside a file reader or other code, enable it with 'u.add_enabled_units'. For details, see https://docs.astropy.org/en/latest/units/combining_and_defining.html [astropy.units.core]
WARNING: UnitsWarning: 'Number' did not parse as fits unit: At col 0, Unit 'Number' not supported by the FITS standard. If this is meant to be a custom unit, define it with 'u.def_unit'. To have it recognized inside a file reader or other code, enable it with 'u.add_enabled_units'. For details, see https://docs.astropy.org/en/latest/units/combining_and_defining.html [astropy.units.core]
WARNING: UnitsWarning: 'Number' did not parse as fits unit: At col 0, Unit 'Number' not supported by the FITS standard. If this is meant to be a custom unit, define it with 'u.def_unit'. To have it recognized inside a file reader or other code, enable it with 'u.add_enabled_units'. For details, see https://docs.astropy.org/en/latest/units/combining_and_defining.html [astropy.units.core]
spectrum
| WAVELENGTH | SIGNAL | MASK | QUALITY | VAR | NDITH |
|---|---|---|---|---|---|
| Angstrom | erg / (Angstrom s cm2) | Number | Number | erg2 / (Angstrom2 s2 cm4) | Number |
| float32 | float32 | float64 | float32 | float32 | float64 |
| 11900.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 11913.400390625 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 11926.7998046875 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 11940.2001953125 | -0.42825955152511597 | 64.0 | 0.924927830696106 | 0.05231768637895584 | 2.0 |
| 11953.599609375 | -0.019433781504631042 | 66.0 | 0.8561765551567078 | 0.010498150251805782 | 2.0 |
| 11967.0 | 0.02915639616549015 | 64.0 | 0.8876305818557739 | 0.003435363294556737 | 4.0 |
| 11980.400390625 | 0.08275385200977325 | 80.0 | 0.0 | 0.0017151220235973597 | 4.0 |
| 11993.7998046875 | 0.018765779212117195 | 64.0 | 0.8546596765518188 | 0.0009618347976356745 | 4.0 |
| 12007.2001953125 | 0.009108440019190311 | 64.0 | 0.8887824416160583 | 0.0005876092473044991 | 4.0 |
| ... | ... | ... | ... | ... | ... |
| 18894.80078125 | 0.004414212889969349 | 64.0 | 0.9155963659286499 | 0.0002704685612116009 | 4.0 |
| 18908.19921875 | -0.034835416823625565 | 64.0 | 0.738968014717102 | 0.0005062822601757944 | 3.0 |
| 18921.599609375 | 0.002581549109891057 | 66.0 | 0.8868578672409058 | 0.0006160042248666286 | 4.0 |
| 18935.0 | -0.03595489263534546 | 66.0 | 0.9000127911567688 | 0.0009402198484167457 | 4.0 |
| 18948.400390625 | -0.0484054833650589 | 64.0 | 0.9134283065795898 | 0.001895991968922317 | 4.0 |
| 18961.80078125 | -0.12392819672822952 | 64.0 | 0.922426164150238 | 0.0031691163312643766 | 3.0 |
| 18975.19921875 | -0.08269069343805313 | 64.0 | 0.8407320976257324 | 0.005587479565292597 | 3.0 |
| 18988.599609375 | -0.14132308959960938 | 66.0 | 0.7666888236999512 | 0.0100048603489995 | 3.0 |
| 19002.0 | -0.33820343017578125 | 66.0 | 0.809532642364502 | 0.01680051162838936 | 4.0 |
spec_header
XTENSION= 'BINTABLE' / binary table extension
BITPIX = 8 / 8-bit bytes
NAXIS = 2 / 2-dimensional binary table
NAXIS1 = 22 / width of table in bytes
NAXIS2 = 531 / number of rows in table
PCOUNT = 0 / size of special data area
GCOUNT = 1 / one data group (required keyword)
TFIELDS = 6 / number of fields in each row
TTYPE1 = 'WAVELENGTH' / label for field 1
TFORM1 = '1E ' / data format of field: 4-byte REAL
TUNIT1 = 'Angstrom' / physical unit of field
TTYPE2 = 'SIGNAL ' / label for field 2
TFORM2 = '1E ' / data format of field: 4-byte REAL
TUNIT2 = 'erg/s/cm2/Angstrom' / physical unit of field
EXTNAME = '94_COMBINED1D_SIGNAL' / name of this binary table extension
WMIN = 11900. / [Angstrom] Minimum wavelength of the binning
BINWIDTH= 13.4 / [Angstrom] Wavelength bin width
BINCOUNT= 531 / Wavelength bin count
TTYPE3 = 'MASK ' / label for field
TFORM3 = '1J ' / format of field
TUNIT3 = 'Number ' / physical unit of field
TTYPE4 = 'QUALITY ' / label for field
TFORM4 = '1E ' / format of field
TUNIT4 = 'Number ' / physical unit of field
TTYPE5 = 'VAR ' / label for field
TFORM5 = '1E ' / format of field
TUNIT5 = 'erg2/s2/cm4/Angstrom2' / physical unit of field
TTYPE6 = 'NDITH ' / label for field
TFORM6 = '1I ' / format of field
TUNIT6 = 'Number ' / physical unit of field
FSCALE = 1.0E-16 / Scaling factor
EXPTIME = 2198.569 / Exposure time
LSF_SIG = 20.28061 / [Angstrom] Std dev of the Gaussian LSF model
EXT_PROF= 'NONE ' / 1D extraction profile used (NONE,OPT_THUMB,OPT_
4. Plot the image of the extracted spectrum#
Tip
As we use astropy.visualization’s quantity_support, matplotlib automatically picks up the axis units from the quantitites we plot.
quantity_support()
<astropy.visualization.units.quantity_support.<locals>.MplQuantityConverter at 0x7f7901756d90>
Note
The 1D combined spectra table contains 6 columns, below are a few highlights:
WAVELENGTH is in Angstroms by default
SIGNAL is the flux and should be multiplied by the FSCALE factor in the header
MASK values can be used to determine which flux bins to discard. MASK = odd and MASK >=64 means the flux bins not be used.
signal_scaled = spectrum['SIGNAL'] * spec_header['FSCALE']
We investigate the MASK column to see which flux bins are recommended to keep vs “Do Not Use”
plt.plot(spectrum['WAVELENGTH'].to(u.micron), spectrum['MASK'])
plt.ylabel('Mask value')
plt.title('Values of MASK by flux bin')
Text(0.5, 1.0, 'Values of MASK by flux bin')
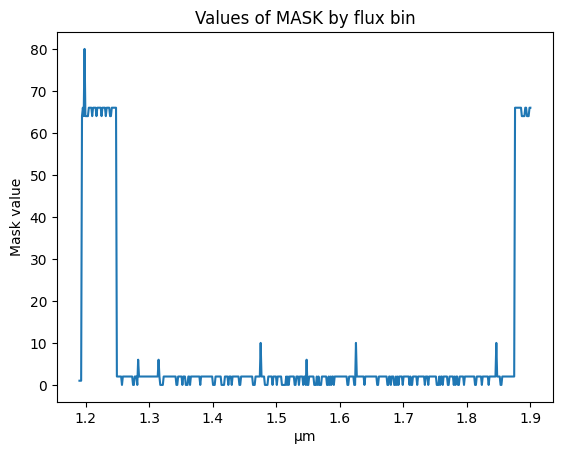
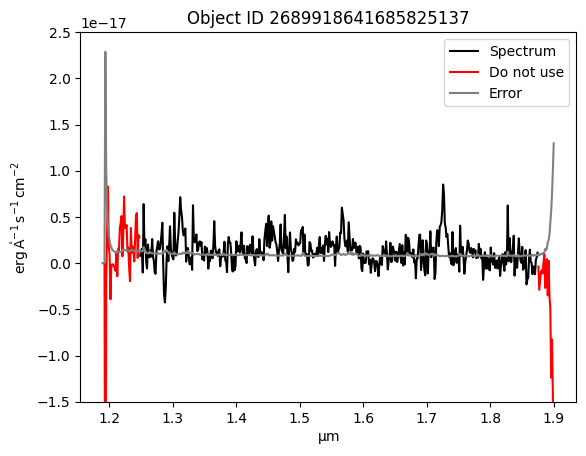
We use the MASK column to create a boolean mask for values to ignore. We use the inverse of this mask to mark the flux bins to use.
bad_mask = (spectrum['MASK'].value % 2 == 1) | (spectrum['MASK'].value >= 64)
plt.plot(spectrum['WAVELENGTH'].to(u.micron), np.ma.masked_where(bad_mask, signal_scaled), color='black', label='Spectrum')
plt.plot(spectrum['WAVELENGTH'], np.ma.masked_where(~bad_mask, signal_scaled), color='red', label='Do not use')
plt.plot(spectrum['WAVELENGTH'], np.sqrt(spectrum['VAR']) * spec_header['FSCALE'], color='grey', label='Error')
plt.legend(loc='upper right')
plt.ylim(-0.15E-16, 0.25E-16)
plt.title(f'Object ID {obj_id}')
Text(0.5, 1.0, 'Object ID 2689918641685825137')
About this Notebook#
Author: Tiffany Meshkat, Anahita Alavi, Anastasia Laity, Andreas Faisst, Brigitta Sipőcz, Dan Masters, Harry Teplitz, Jaladh Singhal, Shoubaneh Hemmati, Vandana Desai
Updated: 2025-03-31
Contact: the IRSA Helpdesk with questions or reporting problems.