Exploring Star Clusters in the Euclid ERO Data#
Learning Goals#
By the end of this tutorial, you will be able to:
• Access the Euclid ERO images using astroquery
• Create cutouts on the large Euclid ERO images directly
• Extract sources on the Euclid image and run photometry tools
• Compare photometry to the Gaia catalog
• Visualize the Euclid ERO image and the Gaia catalog in Firefly
Introduction#
Euclid is a European Space Agency (ESA) space mission with NASA participation, to study the geometry and nature of the dark Universe. As part of its first observations, Euclid publicly released so-called Early Release Observations (ERO) targeting some press-worthy targets on the sky such as star clusters or local galaxies.
In this notebook, we will focus on the ERO data of NGC 6397, a globular cluster 78,000 light years away. (Note that there is another globular cluster, NGC 6254 that can also be used for this analysis - in fact the user can choose which one to use) The goal of this analysis is to extract the Euclid photometry of the stars belonging to the cluster and compare them to the photometry of Gaia. Due to the different pixel scales of the visible (VIS, \(0.1^{\prime\prime}\)) and near-IR (NISP, \(0.3^{\prime\prime}\)) wavelengths, we will first detect and extract the stars in the VIS filter and use their position to subsequently extract the photometry in the NISP (Y, J, H) filters (a method also referred to as forced photometry).
One challenge with Euclid data is their size due to the large sky coverage and small pixel size.
This notebook demonstrates how to download only a cutout of the large Euclid ERO observation image (namely focussing only on the position of the globular cluster. Furthermore, this notebook demonstrates how to extract sources on a large astronomical image and how to measure their photometry across different pixel scales using a very simple implementation of the forced photometry method with positional priors.
Finally, we also demonstrate how to visualize the Euclid images and catalog in Firefly, an open-source web-based UI library for astronomical data archive access and visualization developed at Caltech (https://github.com/Caltech-IPAC/firefly). Firefly is a convenient tool to visualize images similar to DS9 on your local computer, but it can run on a cloud-based science platform.
This notebook is written to be used in Fornax which is a cloud based computing platform using AWS. The advantage of this is that the user does not need to download actuall data, hence the analysis of large datasets is not limited by local computing resources. It also allows to access data across all archives fast and easy.
Data Volume#
The total data volume required for running this notebook is less than 20 MB.
Imports#
Important
We rely on astroquery, firefly_client, photutils, and sep features that have been recently added, so please make sure you have the respective versions v0.4.10, v3.2, v2.0, and v1.4 or newer installed.
# Uncomment the next line to install dependencies if needed.
# !pip install tqdm numpy matplotlib astropy 'photutils>=2.0' 'astroquery>=0.4.10' 'sep>=1.4' 'firefly_client>=3.2'
First, we import all necessary packages.
# General imports
import os
import numpy as np
from tqdm import tqdm
# Astroquery
from astroquery.ipac.irsa import Irsa
from astroquery.gaia import Gaia
# Astropy
from astropy.coordinates import SkyCoord
from astropy import units as u
from astropy.io import fits
from astropy.nddata import Cutout2D
from astropy.wcs import WCS
from astropy.table import Table
from astropy.stats import sigma_clipped_stats
# Photometry tools
import sep
from photutils.detection import DAOStarFinder
from photutils.psf import PSFPhotometry, IterativePSFPhotometry, CircularGaussianSigmaPRF, make_psf_model_image
from photutils.background import LocalBackground, MMMBackground
# Firefly
from firefly_client import FireflyClient
# Matplotlib
import matplotlib.pyplot as plt
import matplotlib as mpl
/home/runner/work/irsa-tutorials/irsa-tutorials/.tox/py311-buildhtml/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Next, we define some parameters for Matplotlib plotting.
## Plotting stuff
mpl.rcParams['font.size'] = 14
mpl.rcParams['axes.labelpad'] = 7
mpl.rcParams['xtick.major.pad'] = 7
mpl.rcParams['ytick.major.pad'] = 7
mpl.rcParams['xtick.minor.visible'] = True
mpl.rcParams['ytick.minor.visible'] = True
mpl.rcParams['xtick.minor.top'] = True
mpl.rcParams['xtick.minor.bottom'] = True
mpl.rcParams['ytick.minor.left'] = True
mpl.rcParams['ytick.minor.right'] = True
mpl.rcParams['xtick.major.size'] = 5
mpl.rcParams['ytick.major.size'] = 5
mpl.rcParams['xtick.minor.size'] = 3
mpl.rcParams['ytick.minor.size'] = 3
mpl.rcParams['xtick.direction'] = 'in'
mpl.rcParams['ytick.direction'] = 'in'
#mpl.rc('text', usetex=True)
mpl.rc('font', family='serif')
mpl.rcParams['xtick.top'] = True
mpl.rcParams['ytick.right'] = True
mpl.rcParams['hatch.linewidth'] = 1
def_cols = plt.rcParams['axes.prop_cycle'].by_key()['color']
Setting up the Environment#
Next, we set up the environment. This includes
setting up an output data directory (will be created if it does not exist)
define the search radius around the target of interest to pull data from the Gaia catalog
define the cutout size that will be used to download a certain part of the Euclid ERO images
Finally, we also define the target of interest here. We can choose between two globular clusters, NGC 6254 and NGC6397, both covered by the Euclid ERO data.
Note that astropy units can be attached to the search_radius and cutout_size.
# create output directory
if os.path.exists("./data/"):
print("Output directory already created.")
else:
print("Creating data directory.")
os.mkdir("./data/")
search_radius = 1.5 * u.arcmin # search radius
cutout_size = 1.5 * u.arcmin # cutout size
coord = SkyCoord.from_name('NGC 6397')
Output directory already created.
Search Euclid ERO Images#
Now, we search for the Euclid ERO images using the astroquery package.
Note that the Euclid ERO images are no in the cloud currently, but we access them directly from IRSA using IRSA’s Simple Image Access (SIA) methods.
Note
The following only works for combined images (either extended or point source stacks). This would not work if there are multiple, let’s say, H-band images of Euclid at a given position. Therefore, no time domain studies here (which is anyway not one of the main goals of Euclid).
Here we use the collection euclid_ero, containing the Euclid ERO images. We first create a SkyCoord object and then query the SIA.
image_tab = Irsa.query_sia(pos=(coord, search_radius), collection='euclid_ero')
print("Number of images available: {}".format(len(image_tab)))
Number of images available: 25
Sort the queried table by wavelength (column em_min). This allows us later when we plot the images to keep them sorted by wavelength (VIS, Y, J, H).
image_tab.sort('em_min')
Let’s inspec the table that was downloaded.
image_tab[0:3]
| s_ra | s_dec | facility_name | instrument_name | dataproduct_subtype | calib_level | dataproduct_type | energy_bandpassname | energy_emband | obs_id | s_resolution | em_min | em_max | em_res_power | proposal_title | access_url | access_format | access_estsize | t_exptime | s_region | obs_collection | obs_intent | algorithm_name | facility_keywords | instrument_keywords | environment_photometric | proposal_id | proposal_pi | proposal_project | target_name | target_type | target_standard | target_moving | target_keywords | obs_release_date | s_xel1 | s_xel2 | s_pixel_scale | position_timedependent | t_min | t_max | t_resolution | t_xel | obs_publisher_did | s_fov | em_xel | pol_states | pol_xel | cloud_access | o_ucd | upload_row_id |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| deg | deg | arcsec | m | m | kbyte | s | deg | arcsec | d | d | s | deg | ||||||||||||||||||||||||||||||||||||||
| float64 | float64 | object | object | object | int16 | object | object | object | object | float64 | float64 | float64 | float64 | object | object | object | int64 | float64 | object | object | object | object | object | object | bool | object | object | object | object | object | bool | bool | object | object | int64 | int64 | float64 | bool | float64 | float64 | float64 | int64 | object | float64 | int64 | object | int64 | object | object | int64 |
| 265.1744234 | -53.6588139 | Euclid | VIS | science | 3 | image | VIS | Optical | VIS-ERO-NGC6397 | 0.16 | 5.5e-07 | 9e-07 | 2.1 | Euclid Early Release Observations | https://irsa.ipac.caltech.edu/data/Euclid/ERO/images/NGC6397/ERO-NGC6397/Euclid-VIS-ERO-NGC6397-LSB.DR3.fits | image/fits | 5184015 | -- | POLYGON ICRS 266.0282156 -54.1557675 266.0082 -53.1559013 264.3406 -53.1559013 264.3205844 -54.1557675 266.0282156 -54.1557675 | euclid_ero | science | coadd | -- | Euclid | NGC 6397 | object | False | False | 2024-05-23 00:00:00 | 36000 | 36000 | 0.1000000000008 | False | -- | -- | -- | -- | ivo://irsa.ipac/euclid_ero?VIS-ERO-NGC6397/LSB | 1.000000000008 | -- | -- | {} | 1 | |||||||
| 265.1744234 | -53.6588139 | Euclid | VIS | weight | 3 | image | VIS | Optical | VIS-ERO-NGC6397 | 0.16 | 5.5e-07 | 9e-07 | 2.1 | Euclid Early Release Observations | https://irsa.ipac.caltech.edu/data/Euclid/ERO/images/NGC6397/ERO-NGC6397/Euclid-VIS-ERO-NGC6397-Flattened.DR3.weight.fits | image/fits | 5184009 | -- | POLYGON ICRS 266.0282156 -54.1557675 266.0082 -53.1559013 264.3406 -53.1559013 264.3205844 -54.1557675 266.0282156 -54.1557675 | euclid_ero | science | coadd | -- | Euclid | NGC 6397 | object | False | False | 2024-05-23 00:00:00 | 36000 | 36000 | 0.1000000000008 | False | -- | -- | -- | -- | ivo://irsa.ipac/euclid_ero?VIS-ERO-NGC6397/Flattened | 1.000000000008 | -- | -- | {} | 1 | |||||||
| 265.1744234 | -53.6588139 | Euclid | VIS | auxiliary | 3 | image | VIS | Optical | VIS-ERO-NGC6397 | 0.16 | 5.5e-07 | 9e-07 | 2.1 | Euclid Early Release Observations | https://irsa.ipac.caltech.edu/data/Euclid/ERO/images/NGC6397/ERO-NGC6397/Euclid-VIS-Mask-ERO-NGC6397-LSB.DR3.fits | image/fits | 5184006 | -- | POLYGON ICRS 266.0282156 -54.1557675 266.0082 -53.1559013 264.3406 -53.1559013 264.3205844 -54.1557675 266.0282156 -54.1557675 | euclid_ero | science | coadd | -- | Euclid | NGC 6397 | object | False | False | 2024-05-23 00:00:00 | 36000 | 36000 | 0.1000000000008 | False | -- | -- | -- | -- | ivo://irsa.ipac/euclid_ero?VIS-ERO-NGC6397/LSB | 1.000000000008 | -- | -- | {} | 1 |
Next, we add additional restrictions to narrow down the images.
The Euclid ERO images come in two different flavors:
Flattened images: idealized for compact sources (for example stars)
LSB images: idealized for low surface brightness objects (for example galaxies)
Maybe counter-intuitively, we select the LSB images here by checking if the file name given in the URL (access_url column) contains that key word. We found that the Flattened images contain many masked pixels.
#sel_basic = np.where( ["Flattened" in tt["access_url"] for tt in image_tab] )[0]
sel_basic = np.where( ["LSB" in tt["access_url"] for tt in image_tab] )[0]
image_tab = image_tab[sel_basic]
Next, we want to check what filteres are available. This can be done by np.unique(), however, in that case it would sort the filters alphabetically. We want to keep the sorting based on the wavelength, therefore we opt for a more complicated way.
idxs = np.unique(image_tab["energy_bandpassname"], return_index=True)[1]
filters = [image_tab["energy_bandpassname"][idx] for idx in sorted(idxs)]
print("Filters: {}".format(filters))
Filters: ['VIS', 'Y', 'J', 'H']
We can now loop throught the filters and collect the images to create a handy summary table with all the data we have. This way we will have an easier time to later access the data.
# Create a dictionary with all the necessary information (science, weight, noise, mask)
summary_table = Table(names=["filter","products","facility_name","instrument_name"] , dtype=[str,str,str,str])
for filt in filters:
sel = np.where(image_tab['energy_bandpassname'] == filt)[0]
products = list( np.unique(image_tab["dataproduct_subtype"][sel].value) )
if "science" in products: # sort so that science is the first in the list. This is the order we create the hdu extensions
products.remove("science")
products.insert(0,"science")
else:
print("WARNING: no science image found!")
print(products)
summary_table.add_row( [filt , ";".join(products), str(np.unique(image_tab["facility_name"][sel].value)[0]), str(np.unique(image_tab["instrument_name"][sel].value)[0])] )
['science', 'auxiliary']
['science', 'auxiliary']
['science', 'auxiliary']
['science', 'auxiliary']
Let’s check out the summary table that we have created. We see that we have all the 4 Euclid bands and what data products are available for each of them.
summary_table
| filter | products | facility_name | instrument_name |
|---|---|---|---|
| str3 | str17 | str6 | str4 |
| VIS | science;auxiliary | Euclid | VIS |
| Y | science;auxiliary | Euclid | NISP |
| J | science;auxiliary | Euclid | NISP |
| H | science;auxiliary | Euclid | NISP |
Create Cutout Images#
Now that we have a list of data products, we can create the cutouts. This is important as the full Euclid ERO images would be too large to run extraction and photometry software on them (they would simply fail due to memory issues).
For each image, we create a cutout around the target of interest, using the cutout_size defined above. The cutouts are then collected into HDUs. That way we can easily access the different data products. Note that we only use the science products as the ancillary products are not needed.
We save the HDU to disk as it will be later used when we visualize the Euclid ERO FITS images in Firefly.
Note
You will notice that Cutout2D can be applied to an URL. That way, it we do not need to download the full image to create a cutout. This is a useful trick to keep in mind when analyzing large images. This makes creating cutout images very fast.
%%time
for ii,filt in tqdm(enumerate(filters)):
products = summary_table[summary_table["filter"] == filt]["products"][0].split(";")
for product in products:
sel = np.where( (image_tab["energy_bandpassname"] == filt) & (image_tab["dataproduct_subtype"] == product) )[0]
with fits.open(image_tab['access_url'][sel[0]], use_fsspec=True) as hdul:
tmp = Cutout2D(hdul[0].section, position=coord, size=cutout_size, wcs=WCS(hdul[0].header)) # create cutout
if (product == "science") & (ii == 0): # if science image, then create a new hdu.
hdu0 = fits.PrimaryHDU(data = tmp.data, header=hdul[0].header)
hdu0.header.update(tmp.wcs.to_header()) # update header with WCS info
hdu0.header["EXTNAME"] = "{}_{}".format(filt,product.upper())
hdu0.header["PRODUCT"] = product.upper()
hdu0.header["FILTER"] = filt.upper()
hdulcutout = fits.HDUList([hdu0])
elif (product == "science") & (ii > 0):
hdu = fits.ImageHDU(data = tmp.data, header=hdul[0].header)
hdu.header.update(tmp.wcs.to_header()) # update header with WCS info
hdu.header["EXTNAME"] = "{}_{}".format(filt,product.upper())
hdu.header["PRODUCT"] = product.upper()
hdu.header["FILTER"] = filt.upper()
hdulcutout.append(hdu)
## Save the HDUL cube:
hdulcutout.writeto("./data/euclid_images_test.fits", overwrite=True)
CPU times: user 1.72 s, sys: 443 ms, total: 2.16 s
Wall time: 19.9 s
0it [00:00, ?it/s]
1it [00:13, 13.60s/it]
2it [00:15, 6.67s/it]
3it [00:18, 4.81s/it]
4it [00:19, 3.63s/it]
4it [00:19, 4.96s/it]
Let’s look at the HDU that we created to check what information we have. You see that all filters are collected in different extensions. Also note the different dimensions of the FITS layers as the pixel scale of VIS and NISP are different.
hdulcutout.info()
Filename: (No file associated with this HDUList)
No. Name Ver Type Cards Dimensions Format
0 VIS_SCIENCE 1 PrimaryHDU 190 (900, 900) float32
1 Y_SCIENCE 1 ImageHDU 191 (300, 300) float32
2 J_SCIENCE 1 ImageHDU 191 (300, 300) float32
3 H_SCIENCE 1 ImageHDU 191 (300, 300) float32
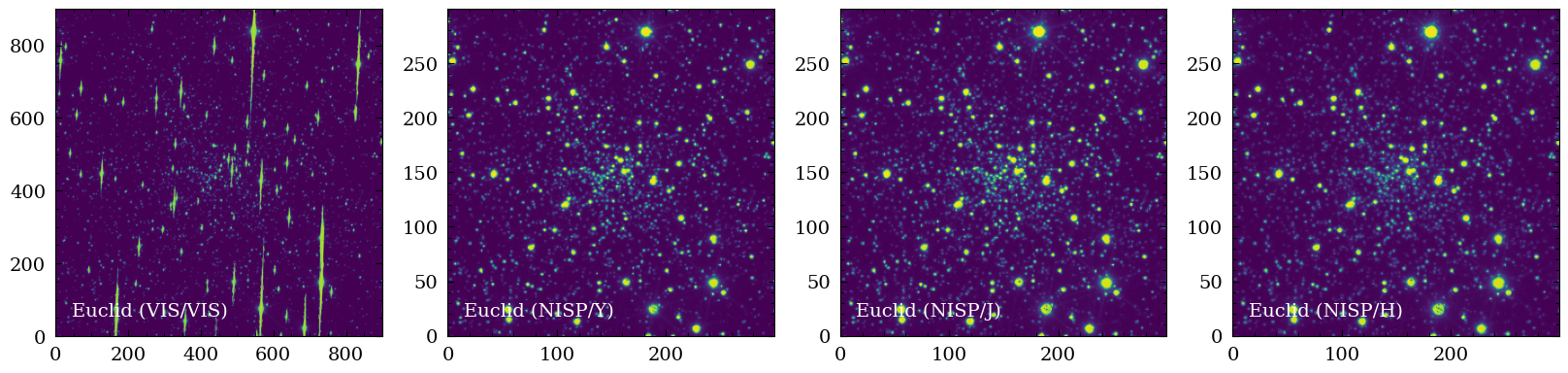
We can now plot the image cutouts that we generated. The globular cluster is clearly visible.
nimages = len(filters) # number of images
ncols = int(4) # number of columns
nrows = int( nimages // ncols ) # number of rows
fig = plt.figure(figsize = (5*ncols,5*nrows) )
axs = [fig.add_subplot(nrows,ncols,ii+1) for ii in range(nimages)]
for ii,filt in enumerate(filters):
img = hdulcutout["{}_SCIENCE".format(filt)].data
axs[ii].imshow(img , origin="lower")
axs[ii].text(0.05,0.05 , "{} ({}/{})".format(summary_table["facility_name"][ii],summary_table["instrument_name"][ii],filt) , fontsize=14 , color="white",
va="bottom", ha="left" , transform=axs[ii].transAxes)
plt.show()
Extract Sources and Measure their Photometry on the VIS Image#
Now that we have the images in memory (and on disk - but we do not need them, yet), we can measure the fluxes of the individual stars. Our simple photometry pipeline has different parts:
First, we are using the Python package
sep(similar to SExtractor) to extract the position of the sources. We do that on the VIS image, which provides the highest resolution.Second, we use
septo perform aperture measurements of the photometry. We will use that to compare the obtained fluxes to our forced photometry methodThird, we apply a PSF fitting technique (using the
photutilsPython package) to improve the photometry measurement
We start by extracting the sources using sep. We first isolate the data that we want to look at (the VIS image only).
## Get Data (this will be replaced later)
img = hdulcutout["VIS_SCIENCE"].data
hdr = hdulcutout["VIS_SCIENCE"].header
img[img == 0] = np.nan
There are some NaN value on the image that we need to mask out. For this we create a mask image that we later feed to sep.
mask = np.isnan(img)
Next, we compute the background statistics what will be used by sep to extract the sources above a certain threshold.
mean, median, std = sigma_clipped_stats(img, sigma=3.0)
print(np.array((mean, median, std)))
[135.95871 99.62191 100.63356]
WARNING: Input data contains invalid values (NaNs or infs), which were automatically clipped. [astropy.stats.sigma_clipping]
Finally, we perform object detection with sep. There are also modules in photutils to do that, however, we found that sep works best here. We output the number of objects found on the image.
objects = sep.extract(img-median, thresh=1.2, err=std, minarea=3, mask=mask, deblend_cont=0.0002, deblend_nthresh=64 )
print("Number of sources extracted: ", len(objects))
Number of sources extracted: 2759
Next, we perform simple aperture photometry on the detected sources. Again, we use the sep package for this. We will use these aperture photometry later to compare to the PSF photometry.
flux, fluxerr, flag = sep.sum_circle(img-median, objects['x'], objects['y'],r=3.0, err=std, gain=1.0)
Now, we use the photutils Python package to perform PSF fitting. Here we assume a simple Gaussian with a FWHM given by psf_fwhm as PSF.
Note
We use a Gaussian PSF here for simplicity. The photometry can be improved by using a pixelated PSF measured directly from the Euclid images (for example by stacking stars).
psf_fwhm = 0.16 # PSF FWHM in arcsec
pixscale = 0.1 # VIS pixel scale in arcsec/px
init_params = Table([objects["x"],objects["y"]] , names=["x","y"]) # initial positions
psf_model = CircularGaussianSigmaPRF(flux=1, sigma=psf_fwhm/pixscale / 2.35)
psf_model.x_0.fixed = True
psf_model.y_0.fixed = True
psf_model.sigma.fixed = False
fit_shape = (5, 5)
psfphot = PSFPhotometry(psf_model,
fit_shape,
finder = DAOStarFinder(fwhm=0.1, threshold=3.*std, exclude_border=True), # not needed because we are using fixed initial positions.
aperture_radius = 4,
progress_bar = True)
After initiating the PSFPhotometry object, we can run the PSF photometry measurement. This can take a while (typically between 1 and 2 minutes).
phot = psfphot(img-median, error=None, mask=mask, init_params=init_params)
Fit source/group: 0%| | 0/2759 [00:00<?, ?it/s]
Fit source/group: 1%| | 23/2759 [00:00<00:12, 225.22it/s]
Fit source/group: 2%|▏ | 46/2759 [00:00<00:12, 216.69it/s]
Fit source/group: 3%|▎ | 70/2759 [00:00<00:11, 224.27it/s]
Fit source/group: 3%|▎ | 93/2759 [00:00<00:15, 169.53it/s]
Fit source/group: 4%|▍ | 118/2759 [00:00<00:13, 191.70it/s]
Fit source/group: 5%|▌ | 142/2759 [00:00<00:12, 203.93it/s]
Fit source/group: 6%|▌ | 164/2759 [00:00<00:12, 204.49it/s]
Fit source/group: 7%|▋ | 187/2759 [00:00<00:12, 211.23it/s]
Fit source/group: 8%|▊ | 210/2759 [00:01<00:11, 215.24it/s]
Fit source/group: 9%|▊ | 235/2759 [00:01<00:11, 223.25it/s]
Fit source/group: 9%|▉ | 259/2759 [00:01<00:11, 226.51it/s]
Fit source/group: 10%|█ | 282/2759 [00:01<00:11, 224.33it/s]
Fit source/group: 11%|█ | 305/2759 [00:01<00:10, 224.01it/s]
Fit source/group: 12%|█▏ | 329/2759 [00:01<00:10, 228.20it/s]
Fit source/group: 13%|█▎ | 353/2759 [00:01<00:10, 229.57it/s]
Fit source/group: 14%|█▎ | 377/2759 [00:01<00:11, 209.94it/s]
Fit source/group: 14%|█▍ | 399/2759 [00:01<00:11, 211.17it/s]
Fit source/group: 15%|█▌ | 423/2759 [00:01<00:10, 216.69it/s]
Fit source/group: 16%|█▌ | 446/2759 [00:02<00:10, 220.42it/s]
Fit source/group: 17%|█▋ | 469/2759 [00:02<00:10, 219.67it/s]
Fit source/group: 18%|█▊ | 492/2759 [00:02<00:10, 220.08it/s]
Fit source/group: 19%|█▊ | 515/2759 [00:02<00:10, 222.37it/s]
Fit source/group: 19%|█▉ | 538/2759 [00:02<00:10, 215.51it/s]
Fit source/group: 20%|██ | 561/2759 [00:02<00:10, 215.25it/s]
Fit source/group: 21%|██ | 583/2759 [00:02<00:10, 215.88it/s]
Fit source/group: 22%|██▏ | 606/2759 [00:02<00:10, 214.55it/s]
Fit source/group: 23%|██▎ | 628/2759 [00:02<00:10, 200.17it/s]
Fit source/group: 24%|██▎ | 652/2759 [00:03<00:10, 208.72it/s]
Fit source/group: 24%|██▍ | 674/2759 [00:03<00:09, 210.03it/s]
Fit source/group: 25%|██▌ | 696/2759 [00:03<00:10, 193.96it/s]
Fit source/group: 26%|██▌ | 719/2759 [00:03<00:10, 203.36it/s]
Fit source/group: 27%|██▋ | 740/2759 [00:03<00:10, 201.66it/s]
Fit source/group: 28%|██▊ | 762/2759 [00:03<00:09, 205.39it/s]
Fit source/group: 28%|██▊ | 785/2759 [00:03<00:09, 211.19it/s]
Fit source/group: 29%|██▉ | 807/2759 [00:03<00:09, 213.26it/s]
Fit source/group: 30%|███ | 829/2759 [00:03<00:09, 211.98it/s]
Fit source/group: 31%|███ | 851/2759 [00:04<00:08, 213.71it/s]
Fit source/group: 32%|███▏ | 873/2759 [00:04<00:08, 214.44it/s]
Fit source/group: 33%|███▎ | 897/2759 [00:04<00:08, 220.48it/s]
Fit source/group: 33%|███▎ | 920/2759 [00:04<00:08, 217.46it/s]
Fit source/group: 34%|███▍ | 944/2759 [00:04<00:08, 222.81it/s]
Fit source/group: 35%|███▌ | 967/2759 [00:04<00:08, 201.68it/s]
Fit source/group: 36%|███▌ | 989/2759 [00:04<00:08, 205.82it/s]
Fit source/group: 37%|███▋ | 1010/2759 [00:04<00:08, 201.28it/s]
Fit source/group: 37%|███▋ | 1031/2759 [00:04<00:08, 200.91it/s]
Fit source/group: 38%|███▊ | 1055/2759 [00:04<00:08, 209.21it/s]
Fit source/group: 39%|███▉ | 1077/2759 [00:05<00:08, 210.10it/s]
Fit source/group: 40%|███▉ | 1099/2759 [00:05<00:07, 211.26it/s]
Fit source/group: 41%|████ | 1123/2759 [00:05<00:07, 218.99it/s]
Fit source/group: 42%|████▏ | 1146/2759 [00:05<00:07, 220.60it/s]
Fit source/group: 42%|████▏ | 1171/2759 [00:05<00:07, 226.27it/s]
Fit source/group: 43%|████▎ | 1194/2759 [00:05<00:06, 225.36it/s]
Fit source/group: 44%|████▍ | 1217/2759 [00:05<00:06, 226.52it/s]
Fit source/group: 45%|████▍ | 1240/2759 [00:05<00:06, 222.86it/s]
Fit source/group: 46%|████▌ | 1264/2759 [00:05<00:06, 226.31it/s]
Fit source/group: 47%|████▋ | 1287/2759 [00:06<00:06, 221.63it/s]
Fit source/group: 47%|████▋ | 1310/2759 [00:06<00:06, 210.66it/s]
Fit source/group: 48%|████▊ | 1332/2759 [00:06<00:06, 212.28it/s]
Fit source/group: 49%|████▉ | 1354/2759 [00:06<00:06, 211.86it/s]
Fit source/group: 50%|████▉ | 1376/2759 [00:06<00:06, 208.41it/s]
Fit source/group: 51%|█████ | 1397/2759 [00:06<00:06, 208.47it/s]
Fit source/group: 51%|█████▏ | 1418/2759 [00:06<00:06, 196.45it/s]
Fit source/group: 52%|█████▏ | 1440/2759 [00:06<00:06, 202.50it/s]
Fit source/group: 53%|█████▎ | 1465/2759 [00:06<00:06, 214.60it/s]
Fit source/group: 54%|█████▍ | 1488/2759 [00:06<00:05, 217.62it/s]
Fit source/group: 55%|█████▍ | 1510/2759 [00:07<00:05, 214.25it/s]
Fit source/group: 56%|█████▌ | 1532/2759 [00:07<00:06, 196.32it/s]
Fit source/group: 56%|█████▋ | 1554/2759 [00:07<00:05, 202.01it/s]
Fit source/group: 57%|█████▋ | 1578/2759 [00:07<00:05, 211.73it/s]
Fit source/group: 58%|█████▊ | 1602/2759 [00:07<00:05, 217.69it/s]
Fit source/group: 59%|█████▉ | 1624/2759 [00:07<00:05, 210.61it/s]
Fit source/group: 60%|█████▉ | 1646/2759 [00:07<00:05, 205.21it/s]
Fit source/group: 60%|██████ | 1668/2759 [00:07<00:05, 208.38it/s]
Fit source/group: 61%|██████▏ | 1691/2759 [00:07<00:05, 213.08it/s]
Fit source/group: 62%|██████▏ | 1715/2759 [00:08<00:04, 220.68it/s]
Fit source/group: 63%|██████▎ | 1738/2759 [00:08<00:04, 221.15it/s]
Fit source/group: 64%|██████▍ | 1761/2759 [00:08<00:04, 208.31it/s]
Fit source/group: 65%|██████▍ | 1783/2759 [00:08<00:04, 199.80it/s]
Fit source/group: 65%|██████▌ | 1806/2759 [00:08<00:04, 207.24it/s]
Fit source/group: 66%|██████▋ | 1828/2759 [00:08<00:04, 208.81it/s]
Fit source/group: 67%|██████▋ | 1853/2759 [00:08<00:04, 219.77it/s]
Fit source/group: 68%|██████▊ | 1877/2759 [00:08<00:03, 223.58it/s]
Fit source/group: 69%|██████▉ | 1900/2759 [00:08<00:03, 222.39it/s]
Fit source/group: 70%|██████▉ | 1924/2759 [00:09<00:03, 226.33it/s]
Fit source/group: 71%|███████ | 1947/2759 [00:09<00:03, 221.43it/s]
Fit source/group: 71%|███████▏ | 1970/2759 [00:09<00:03, 222.87it/s]
Fit source/group: 72%|███████▏ | 1993/2759 [00:09<00:03, 202.06it/s]
Fit source/group: 73%|███████▎ | 2016/2759 [00:09<00:03, 209.10it/s]
Fit source/group: 74%|███████▍ | 2041/2759 [00:09<00:03, 218.14it/s]
Fit source/group: 75%|███████▍ | 2064/2759 [00:09<00:03, 212.06it/s]
Fit source/group: 76%|███████▌ | 2086/2759 [00:09<00:03, 193.13it/s]
Fit source/group: 76%|███████▋ | 2106/2759 [00:09<00:03, 190.12it/s]
Fit source/group: 77%|███████▋ | 2128/2759 [00:10<00:03, 197.82it/s]
Fit source/group: 78%|███████▊ | 2152/2759 [00:10<00:02, 207.99it/s]
Fit source/group: 79%|███████▉ | 2176/2759 [00:10<00:02, 216.87it/s]
Fit source/group: 80%|███████▉ | 2199/2759 [00:10<00:02, 220.21it/s]
Fit source/group: 81%|████████ | 2224/2759 [00:10<00:02, 226.87it/s]
Fit source/group: 81%|████████▏ | 2248/2759 [00:10<00:02, 230.16it/s]
Fit source/group: 82%|████████▏ | 2274/2759 [00:10<00:02, 235.41it/s]
Fit source/group: 83%|████████▎ | 2298/2759 [00:10<00:01, 235.25it/s]
Fit source/group: 84%|████████▍ | 2323/2759 [00:10<00:01, 236.30it/s]
Fit source/group: 85%|████████▌ | 2347/2759 [00:10<00:01, 234.67it/s]
Fit source/group: 86%|████████▌ | 2373/2759 [00:11<00:01, 240.93it/s]
Fit source/group: 87%|████████▋ | 2398/2759 [00:11<00:01, 236.50it/s]
Fit source/group: 88%|████████▊ | 2422/2759 [00:11<00:01, 235.75it/s]
Fit source/group: 89%|████████▊ | 2446/2759 [00:11<00:01, 202.72it/s]
Fit source/group: 90%|████████▉ | 2470/2759 [00:11<00:01, 211.42it/s]
Fit source/group: 90%|█████████ | 2492/2759 [00:11<00:01, 183.51it/s]
Fit source/group: 91%|█████████ | 2512/2759 [00:11<00:01, 176.48it/s]
Fit source/group: 92%|█████████▏| 2531/2759 [00:12<00:01, 149.10it/s]
Fit source/group: 93%|█████████▎| 2553/2759 [00:12<00:01, 164.14it/s]
Fit source/group: 93%|█████████▎| 2571/2759 [00:12<00:01, 146.35it/s]
Fit source/group: 94%|█████████▍| 2587/2759 [00:12<00:01, 124.74it/s]
Fit source/group: 94%|█████████▍| 2606/2759 [00:12<00:01, 130.40it/s]
Fit source/group: 95%|█████████▍| 2620/2759 [00:12<00:01, 121.28it/s]
Fit source/group: 95%|█████████▌| 2633/2759 [00:12<00:01, 112.66it/s]
Fit source/group: 96%|█████████▌| 2646/2759 [00:12<00:00, 115.98it/s]
Fit source/group: 96%|█████████▋| 2659/2759 [00:13<00:00, 119.30it/s]
Fit source/group: 97%|█████████▋| 2672/2759 [00:13<00:00, 120.57it/s]
Fit source/group: 97%|█████████▋| 2685/2759 [00:13<00:00, 120.21it/s]
Fit source/group: 98%|█████████▊| 2698/2759 [00:13<00:00, 87.52it/s]
Fit source/group: 98%|█████████▊| 2711/2759 [00:13<00:00, 96.49it/s]
Fit source/group: 99%|█████████▊| 2723/2759 [00:13<00:00, 98.92it/s]
Fit source/group: 99%|█████████▉| 2745/2759 [00:13<00:00, 127.67it/s]
Fit source/group: 100%|██████████| 2759/2759 [00:13<00:00, 198.20it/s]
WARNING: One or more fit(s) may not have converged. Please check the "flags" column in the output table. [photutils.psf.photometry]
Once this is done, we can create a residual image.
resimage = psfphot.make_residual_image(data = img-median, psf_shape = (9, 9))
Add model sources: 0%| | 0/2759 [00:00<?, ?it/s]
Add model sources: 18%|█▊ | 503/2759 [00:00<00:00, 5019.12it/s]
Add model sources: 37%|███▋ | 1028/2759 [00:00<00:00, 5153.78it/s]
Add model sources: 58%|█████▊ | 1596/2759 [00:00<00:00, 5390.49it/s]
Add model sources: 77%|███████▋ | 2136/2759 [00:00<00:00, 5378.52it/s]
Add model sources: 98%|█████████▊| 2704/2759 [00:00<00:00, 5484.60it/s]
Add model sources: 100%|██████████| 2759/2759 [00:00<00:00, 5388.76it/s]
We now want to add the best-fit coordinates (R.A. and Decl.) to the VIS photometry catalog. For this, we have to convert the image coordinates into sky coordinates using the WCS information. We will need these coordinates because we want to use them as positional priors for the photometry measurement on the NISP images.
## Add coordinates to catalog
wcs1 = WCS(hdr) # VIS
radec = wcs1.all_pix2world(phot["x_fit"],phot["y_fit"],0)
phot["ra_fit"] = radec[0]
phot["dec_fit"] = radec[1]
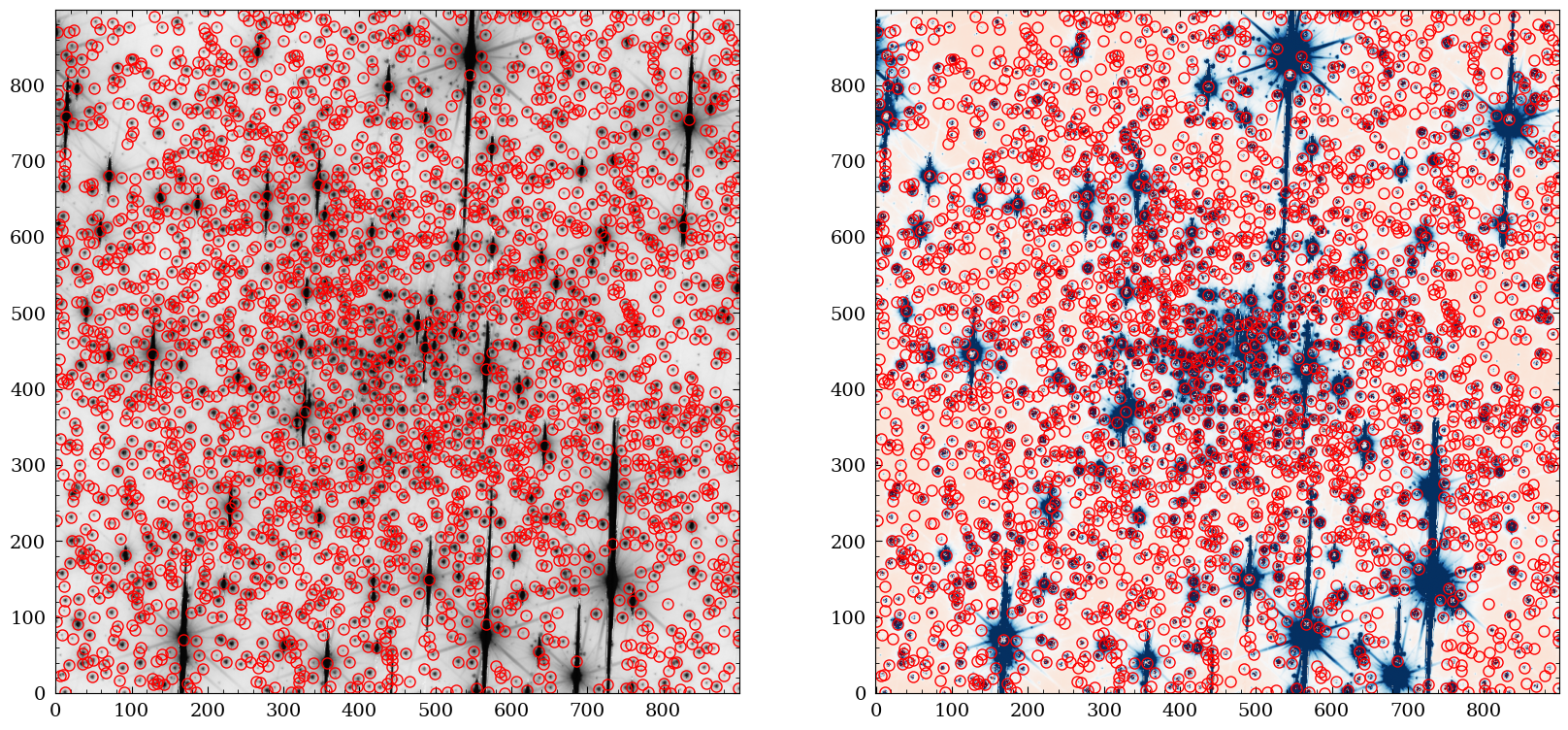
Finally, we plot the VIS image and the residual with the extracted sources overlaid.
fig = plt.figure(figsize=(20,10))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.imshow(np.log10(img), cmap="Greys", origin="lower")
ax1.plot(phot["x_fit"], phot["y_fit"] , "o", markersize=8 , markeredgecolor="red", fillstyle="none")
ax2.imshow(resimage,vmin=-5*std, vmax=5*std, cmap="RdBu", origin="lower")
ax2.plot(phot["x_fit"], phot["y_fit"] , "o", markersize=8 , markeredgecolor="red", fillstyle="none")
plt.show()
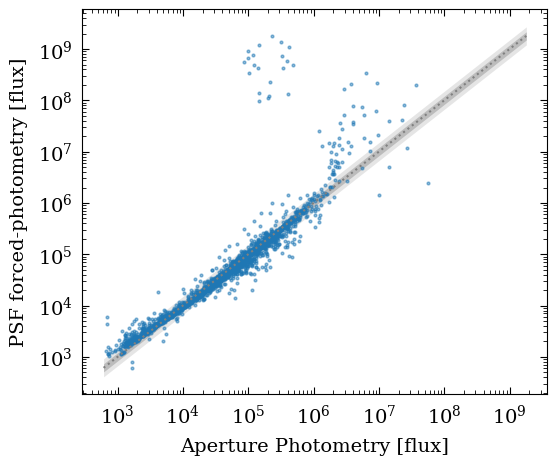
As an additional check, we can compare the aperture photometry and the PSF photometry. We should find a good agreement between those two measurement methods. However, note that the PSF photometry should do a better job in deblending the fluxes of sources that are close by.
x = objects["flux"]
y = phot["flux_fit"]
fig = plt.figure(figsize=(6,5))
ax1 = fig.add_subplot(1,1,1)
ax1.plot(x , y , "o", markersize=2, alpha=0.5)
minlim = np.nanmin(np.concatenate((x,y)))
maxlim = np.nanmax(np.concatenate((x,y)))
ax1.fill_between(np.asarray([minlim,maxlim]),np.asarray([minlim,maxlim])/1.5,np.asarray([minlim,maxlim])*1.5, color="gray", alpha=0.2, linewidth=0)
ax1.fill_between(np.asarray([minlim,maxlim]),np.asarray([minlim,maxlim])/1.2,np.asarray([minlim,maxlim])*1.2, color="gray", alpha=0.4, linewidth=0)
ax1.plot(np.asarray([minlim,maxlim]),np.asarray([minlim,maxlim]), ":", color="gray")
ax1.set_xlabel("Aperture Photometry [flux]")
ax1.set_ylabel("PSF forced-photometry [flux]")
ax1.set_xscale('log')
ax1.set_yscale('log')
plt.show()
Measure the Photometry on the NISP Images#
We now have the photometry and the position of sources on the VIS image. We can now proceed with similar steps on the NISP images. Because the NISP PSF and pixel scale are larger that those of the VIS images, we utilize the advantage of position prior-based forced photometry. For this, we use the positions of the VIS measurements and perform PSF fitting on the NISP image using these priors.
The steps below are almost identical to the ones applied to the VIS images.
We first isolate the data, which is in this case the NISP H-band filter. Note that this is an arbitrary choice and you should be encouraged to try other filters as well!
img2 = hdulcutout["H_SCIENCE"].data
hdr2 = hdulcutout["H_SCIENCE"].header
img2[img2 == 0] = np.nan
We again need to create a mask that will be fed to the PSF fitting module.
mask2 = np.isnan(img2)
… and we also get some statistics on the sky background.
mean2, median2, std2 = sigma_clipped_stats(img2, sigma=3.0)
print(np.array((mean2, median2, std2)))
[2626.3018 1889.8518 2043.9841]
Now, we need to obtain the (x,y) image coordinates on the NISP image that correspond to the extracted sources on the VIS image. We use the WCS information from the NISP image for this case and apply it to the sky coordinates obtained on the VIS image.
wcs = WCS(hdr) # VIS
wcs2 = WCS(hdr2) # NISP
radec = wcs.all_pix2world(objects["x"],objects["y"], 0)
xy = wcs2.all_world2pix(radec[0],radec[1],0)
Having all this set up, we can now again perform the PSF photometry using PSFPhotometry() from the photutils package. This again can take a while, typically 1 minute.
psf_fwhm = 0.3 # arcsec
pixscale = 0.3 # arcsec/px
init_params = Table([xy[0],xy[1]] , names=["x","y"]) # initial positions
psf_model = CircularGaussianSigmaPRF(flux=1, sigma=psf_fwhm/pixscale / 2.35)
psf_model.x_0.fixed = True
psf_model.y_0.fixed = True
psf_model.sigma.fixed = False
fit_shape = (3, 3)
psfphot2 = PSFPhotometry(psf_model,
fit_shape,
finder = DAOStarFinder(fwhm=0.1, threshold=3.*std2, exclude_border=True), # not needed because we are using fixed initial positions.
aperture_radius = 4,
progress_bar = True)
phot2 = psfphot2(img2-median2, error=None, mask=mask2, init_params=init_params)
resimage2 = psfphot2.make_residual_image(data = img2-median2, psf_shape = (3, 3))
Fit source/group: 0%| | 0/2759 [00:00<?, ?it/s]
Fit source/group: 0%| | 7/2759 [00:00<00:41, 66.97it/s]
Fit source/group: 1%| | 20/2759 [00:00<00:27, 99.06it/s]
Fit source/group: 1%|▏ | 41/2759 [00:00<00:21, 125.75it/s]
Fit source/group: 2%|▏ | 55/2759 [00:00<00:23, 115.20it/s]
Fit source/group: 3%|▎ | 75/2759 [00:00<00:21, 126.64it/s]
Fit source/group: 3%|▎ | 88/2759 [00:00<00:25, 104.53it/s]
Fit source/group: 4%|▎ | 101/2759 [00:00<00:24, 109.60it/s]
Fit source/group: 4%|▍ | 114/2759 [00:01<00:25, 103.67it/s]
Fit source/group: 5%|▍ | 126/2759 [00:01<00:24, 107.43it/s]
Fit source/group: 5%|▌ | 140/2759 [00:01<00:25, 104.35it/s]
Fit source/group: 5%|▌ | 151/2759 [00:01<00:24, 105.45it/s]
Fit source/group: 6%|▌ | 162/2759 [00:01<00:26, 99.70it/s]
Fit source/group: 6%|▋ | 173/2759 [00:01<00:28, 90.81it/s]
Fit source/group: 7%|▋ | 192/2759 [00:01<00:24, 105.89it/s]
Fit source/group: 7%|▋ | 206/2759 [00:01<00:22, 113.26it/s]
Fit source/group: 8%|▊ | 228/2759 [00:02<00:18, 139.71it/s]
Fit source/group: 9%|▉ | 243/2759 [00:02<00:20, 124.37it/s]
Fit source/group: 9%|▉ | 259/2759 [00:02<00:19, 126.34it/s]
Fit source/group: 10%|▉ | 273/2759 [00:02<00:21, 118.22it/s]
Fit source/group: 10%|█ | 287/2759 [00:02<00:20, 122.71it/s]
Fit source/group: 11%|█ | 301/2759 [00:02<00:19, 125.83it/s]
Fit source/group: 11%|█▏ | 314/2759 [00:02<00:25, 97.39it/s]
Fit source/group: 12%|█▏ | 325/2759 [00:02<00:25, 95.47it/s]
Fit source/group: 12%|█▏ | 344/2759 [00:03<00:20, 117.40it/s]
Fit source/group: 13%|█▎ | 361/2759 [00:03<00:19, 125.32it/s]
Fit source/group: 14%|█▎ | 375/2759 [00:03<00:20, 114.35it/s]
Fit source/group: 14%|█▍ | 390/2759 [00:03<00:19, 118.76it/s]
Fit source/group: 15%|█▍ | 403/2759 [00:03<00:19, 120.73it/s]
Fit source/group: 15%|█▌ | 422/2759 [00:03<00:16, 137.88it/s]
Fit source/group: 16%|█▌ | 437/2759 [00:03<00:16, 137.68it/s]
Fit source/group: 16%|█▋ | 452/2759 [00:03<00:16, 136.92it/s]
Fit source/group: 17%|█▋ | 466/2759 [00:04<00:18, 123.75it/s]
Fit source/group: 17%|█▋ | 479/2759 [00:04<00:18, 123.08it/s]
Fit source/group: 18%|█▊ | 498/2759 [00:04<00:16, 140.82it/s]
Fit source/group: 19%|█▊ | 513/2759 [00:04<00:17, 124.96it/s]
Fit source/group: 19%|█▉ | 528/2759 [00:04<00:17, 128.38it/s]
Fit source/group: 20%|█▉ | 542/2759 [00:04<00:19, 116.64it/s]
Fit source/group: 20%|██ | 555/2759 [00:04<00:20, 108.83it/s]
Fit source/group: 21%|██ | 568/2759 [00:04<00:19, 113.98it/s]
Fit source/group: 21%|██ | 580/2759 [00:05<00:20, 107.15it/s]
Fit source/group: 21%|██▏ | 592/2759 [00:05<00:19, 109.40it/s]
Fit source/group: 22%|██▏ | 604/2759 [00:05<00:21, 101.80it/s]
Fit source/group: 22%|██▏ | 615/2759 [00:05<00:26, 81.17it/s]
Fit source/group: 23%|██▎ | 634/2759 [00:05<00:21, 97.32it/s]
Fit source/group: 24%|██▍ | 656/2759 [00:05<00:16, 125.04it/s]
Fit source/group: 24%|██▍ | 670/2759 [00:05<00:18, 116.03it/s]
Fit source/group: 25%|██▍ | 683/2759 [00:05<00:17, 118.37it/s]
Fit source/group: 25%|██▌ | 696/2759 [00:06<00:18, 110.62it/s]
Fit source/group: 26%|██▌ | 708/2759 [00:06<00:23, 87.95it/s]
Fit source/group: 26%|██▌ | 720/2759 [00:06<00:22, 89.58it/s]
Fit source/group: 27%|██▋ | 733/2759 [00:06<00:20, 98.46it/s]
Fit source/group: 27%|██▋ | 747/2759 [00:06<00:18, 107.25it/s]
Fit source/group: 28%|██▊ | 759/2759 [00:06<00:21, 93.59it/s]
Fit source/group: 28%|██▊ | 778/2759 [00:06<00:18, 109.29it/s]
Fit source/group: 29%|██▉ | 796/2759 [00:07<00:16, 115.95it/s]
Fit source/group: 30%|██▉ | 816/2759 [00:07<00:14, 135.23it/s]
Fit source/group: 30%|███ | 831/2759 [00:07<00:17, 112.84it/s]
Fit source/group: 31%|███ | 845/2759 [00:07<00:16, 117.54it/s]
Fit source/group: 31%|███ | 858/2759 [00:07<00:15, 119.84it/s]
Fit source/group: 32%|███▏ | 871/2759 [00:07<00:18, 103.68it/s]
Fit source/group: 32%|███▏ | 883/2759 [00:07<00:20, 92.88it/s]
Fit source/group: 32%|███▏ | 895/2759 [00:08<00:18, 98.79it/s]
Fit source/group: 33%|███▎ | 908/2759 [00:08<00:17, 105.49it/s]
Fit source/group: 33%|███▎ | 921/2759 [00:08<00:16, 111.28it/s]
Fit source/group: 34%|███▍ | 934/2759 [00:08<00:15, 115.19it/s]
Fit source/group: 34%|███▍ | 948/2759 [00:08<00:14, 121.10it/s]
Fit source/group: 35%|███▍ | 961/2759 [00:08<00:16, 110.34it/s]
Fit source/group: 35%|███▌ | 973/2759 [00:08<00:17, 102.70it/s]
Fit source/group: 36%|███▌ | 984/2759 [00:08<00:20, 87.86it/s]
Fit source/group: 36%|███▌ | 994/2759 [00:09<00:20, 84.66it/s]
Fit source/group: 37%|███▋ | 1009/2759 [00:09<00:17, 99.44it/s]
Fit source/group: 37%|███▋ | 1025/2759 [00:09<00:15, 110.19it/s]
Fit source/group: 38%|███▊ | 1044/2759 [00:09<00:14, 118.82it/s]
Fit source/group: 38%|███▊ | 1057/2759 [00:09<00:15, 109.44it/s]
Fit source/group: 39%|███▉ | 1072/2759 [00:09<00:14, 116.04it/s]
Fit source/group: 39%|███▉ | 1085/2759 [00:09<00:14, 118.97it/s]
Fit source/group: 40%|███▉ | 1099/2759 [00:09<00:13, 123.18it/s]
Fit source/group: 40%|████ | 1112/2759 [00:09<00:14, 111.22it/s]
Fit source/group: 41%|████ | 1124/2759 [00:10<00:14, 113.38it/s]
Fit source/group: 41%|████ | 1136/2759 [00:10<00:15, 106.08it/s]
Fit source/group: 42%|████▏ | 1147/2759 [00:10<00:16, 99.99it/s]
Fit source/group: 42%|████▏ | 1161/2759 [00:10<00:14, 109.28it/s]
Fit source/group: 43%|████▎ | 1174/2759 [00:10<00:13, 114.22it/s]
Fit source/group: 43%|████▎ | 1186/2759 [00:10<00:13, 115.65it/s]
Fit source/group: 43%|████▎ | 1198/2759 [00:10<00:13, 111.98it/s]
Fit source/group: 44%|████▍ | 1210/2759 [00:10<00:16, 94.72it/s]
Fit source/group: 44%|████▍ | 1221/2759 [00:11<00:16, 91.43it/s]
Fit source/group: 45%|████▍ | 1232/2759 [00:11<00:17, 89.25it/s]
Fit source/group: 45%|████▌ | 1244/2759 [00:11<00:15, 95.95it/s]
Fit source/group: 46%|████▌ | 1257/2759 [00:11<00:14, 102.95it/s]
Fit source/group: 46%|████▌ | 1276/2759 [00:11<00:11, 126.15it/s]
Fit source/group: 47%|████▋ | 1290/2759 [00:11<00:11, 128.19it/s]
Fit source/group: 47%|████▋ | 1304/2759 [00:11<00:12, 118.07it/s]
Fit source/group: 48%|████▊ | 1317/2759 [00:11<00:13, 109.97it/s]
Fit source/group: 48%|████▊ | 1329/2759 [00:12<00:13, 103.63it/s]
Fit source/group: 49%|████▊ | 1340/2759 [00:12<00:14, 98.04it/s]
Fit source/group: 49%|████▉ | 1351/2759 [00:12<00:14, 95.71it/s]
Fit source/group: 49%|████▉ | 1362/2759 [00:12<00:14, 98.65it/s]
Fit source/group: 50%|████▉ | 1373/2759 [00:12<00:15, 90.32it/s]
Fit source/group: 50%|█████ | 1383/2759 [00:12<00:17, 80.20it/s]
Fit source/group: 50%|█████ | 1393/2759 [00:12<00:16, 81.05it/s]
Fit source/group: 51%|█████ | 1407/2759 [00:12<00:14, 90.79it/s]
Fit source/group: 51%|█████▏ | 1417/2759 [00:13<00:16, 80.76it/s]
Fit source/group: 52%|█████▏ | 1439/2759 [00:13<00:11, 111.92it/s]
Fit source/group: 53%|█████▎ | 1452/2759 [00:13<00:11, 115.05it/s]
Fit source/group: 53%|█████▎ | 1474/2759 [00:13<00:09, 141.64it/s]
Fit source/group: 54%|█████▍ | 1489/2759 [00:13<00:08, 143.84it/s]
Fit source/group: 55%|█████▍ | 1504/2759 [00:13<00:08, 142.30it/s]
Fit source/group: 55%|█████▌ | 1519/2759 [00:13<00:09, 124.49it/s]
Fit source/group: 56%|█████▌ | 1533/2759 [00:13<00:11, 107.15it/s]
Fit source/group: 56%|█████▌ | 1545/2759 [00:14<00:11, 109.91it/s]
Fit source/group: 56%|█████▋ | 1558/2759 [00:14<00:10, 114.24it/s]
Fit source/group: 57%|█████▋ | 1570/2759 [00:14<00:11, 107.40it/s]
Fit source/group: 58%|█████▊ | 1589/2759 [00:14<00:09, 128.17it/s]
Fit source/group: 58%|█████▊ | 1603/2759 [00:14<00:09, 126.84it/s]
Fit source/group: 59%|█████▊ | 1617/2759 [00:14<00:10, 107.36it/s]
Fit source/group: 59%|█████▉ | 1629/2759 [00:14<00:10, 109.30it/s]
Fit source/group: 59%|█████▉ | 1641/2759 [00:14<00:11, 99.37it/s]
Fit source/group: 60%|█████▉ | 1652/2759 [00:15<00:11, 94.04it/s]
Fit source/group: 60%|██████ | 1665/2759 [00:15<00:11, 94.24it/s]
Fit source/group: 61%|██████ | 1678/2759 [00:15<00:10, 101.77it/s]
Fit source/group: 61%|██████▏ | 1690/2759 [00:15<00:10, 105.20it/s]
Fit source/group: 62%|██████▏ | 1708/2759 [00:15<00:09, 115.43it/s]
Fit source/group: 62%|██████▏ | 1721/2759 [00:15<00:08, 118.69it/s]
Fit source/group: 63%|██████▎ | 1734/2759 [00:15<00:09, 109.29it/s]
Fit source/group: 63%|██████▎ | 1748/2759 [00:15<00:08, 116.58it/s]
Fit source/group: 64%|██████▍ | 1760/2759 [00:16<00:10, 97.79it/s]
Fit source/group: 64%|██████▍ | 1771/2759 [00:16<00:10, 94.91it/s]
Fit source/group: 65%|██████▍ | 1781/2759 [00:16<00:11, 83.96it/s]
Fit source/group: 65%|██████▍ | 1791/2759 [00:16<00:11, 82.35it/s]
Fit source/group: 66%|██████▌ | 1809/2759 [00:16<00:09, 100.88it/s]
Fit source/group: 66%|██████▋ | 1829/2759 [00:16<00:07, 117.12it/s]
Fit source/group: 67%|██████▋ | 1842/2759 [00:16<00:08, 110.10it/s]
Fit source/group: 67%|██████▋ | 1854/2759 [00:16<00:08, 103.33it/s]
Fit source/group: 68%|██████▊ | 1866/2759 [00:17<00:09, 98.58it/s]
Fit source/group: 68%|██████▊ | 1879/2759 [00:17<00:08, 105.87it/s]
Fit source/group: 69%|██████▊ | 1893/2759 [00:17<00:07, 113.40it/s]
Fit source/group: 69%|██████▉ | 1907/2759 [00:17<00:07, 115.74it/s]
Fit source/group: 70%|██████▉ | 1919/2759 [00:17<00:08, 99.36it/s]
Fit source/group: 70%|███████ | 1932/2759 [00:17<00:07, 106.27it/s]
Fit source/group: 70%|███████ | 1944/2759 [00:17<00:08, 93.22it/s]
Fit source/group: 71%|███████ | 1954/2759 [00:18<00:08, 90.19it/s]
Fit source/group: 72%|███████▏ | 1974/2759 [00:18<00:06, 116.50it/s]
Fit source/group: 72%|███████▏ | 1987/2759 [00:18<00:08, 92.94it/s]
Fit source/group: 72%|███████▏ | 1998/2759 [00:18<00:08, 90.52it/s]
Fit source/group: 73%|███████▎ | 2009/2759 [00:18<00:07, 94.40it/s]
Fit source/group: 73%|███████▎ | 2020/2759 [00:18<00:08, 91.65it/s]
Fit source/group: 74%|███████▎ | 2031/2759 [00:18<00:07, 94.33it/s]
Fit source/group: 74%|███████▍ | 2046/2759 [00:18<00:06, 104.40it/s]
Fit source/group: 75%|███████▍ | 2059/2759 [00:19<00:06, 110.80it/s]
Fit source/group: 75%|███████▌ | 2074/2759 [00:19<00:06, 111.21it/s]
Fit source/group: 76%|███████▌ | 2086/2759 [00:19<00:06, 105.29it/s]
Fit source/group: 76%|███████▌ | 2098/2759 [00:19<00:06, 100.66it/s]
Fit source/group: 77%|███████▋ | 2117/2759 [00:19<00:05, 116.27it/s]
Fit source/group: 77%|███████▋ | 2132/2759 [00:19<00:05, 122.86it/s]
Fit source/group: 78%|███████▊ | 2145/2759 [00:19<00:04, 123.73it/s]
Fit source/group: 78%|███████▊ | 2158/2759 [00:19<00:05, 104.86it/s]
Fit source/group: 79%|███████▊ | 2170/2759 [00:20<00:05, 100.92it/s]
Fit source/group: 79%|███████▉ | 2182/2759 [00:20<00:05, 104.84it/s]
Fit source/group: 80%|███████▉ | 2197/2759 [00:20<00:04, 113.55it/s]
Fit source/group: 80%|████████ | 2210/2759 [00:20<00:04, 116.23it/s]
Fit source/group: 81%|████████ | 2222/2759 [00:20<00:05, 96.65it/s]
Fit source/group: 81%|████████ | 2234/2759 [00:20<00:05, 93.69it/s]
Fit source/group: 81%|████████▏ | 2246/2759 [00:20<00:05, 91.21it/s]
Fit source/group: 82%|████████▏ | 2264/2759 [00:20<00:04, 107.56it/s]
Fit source/group: 82%|████████▏ | 2276/2759 [00:21<00:04, 107.76it/s]
Fit source/group: 83%|████████▎ | 2288/2759 [00:21<00:04, 102.96it/s]
Fit source/group: 84%|████████▎ | 2307/2759 [00:21<00:03, 123.01it/s]
Fit source/group: 84%|████████▍ | 2321/2759 [00:21<00:03, 123.60it/s]
Fit source/group: 85%|████████▍ | 2339/2759 [00:21<00:03, 127.01it/s]
Fit source/group: 85%|████████▌ | 2352/2759 [00:21<00:03, 117.72it/s]
Fit source/group: 86%|████████▌ | 2364/2759 [00:21<00:03, 99.46it/s]
Fit source/group: 86%|████████▌ | 2375/2759 [00:22<00:04, 87.79it/s]
Fit source/group: 86%|████████▋ | 2385/2759 [00:22<00:04, 86.25it/s]
Fit source/group: 87%|████████▋ | 2397/2759 [00:22<00:04, 87.94it/s]
Fit source/group: 87%|████████▋ | 2412/2759 [00:22<00:03, 98.33it/s]
Fit source/group: 88%|████████▊ | 2426/2759 [00:22<00:03, 107.38it/s]
Fit source/group: 88%|████████▊ | 2438/2759 [00:22<00:03, 93.69it/s]
Fit source/group: 89%|████████▉ | 2451/2759 [00:22<00:03, 101.56it/s]
Fit source/group: 89%|████████▉ | 2462/2759 [00:22<00:03, 88.43it/s]
Fit source/group: 90%|████████▉ | 2473/2759 [00:23<00:03, 90.80it/s]
Fit source/group: 90%|█████████ | 2485/2759 [00:23<00:02, 97.05it/s]
Fit source/group: 90%|█████████ | 2496/2759 [00:23<00:03, 79.29it/s]
Fit source/group: 91%|█████████ | 2517/2759 [00:23<00:02, 107.81it/s]
Fit source/group: 92%|█████████▏| 2530/2759 [00:23<00:02, 84.15it/s]
Fit source/group: 92%|█████████▏| 2541/2759 [00:23<00:02, 83.61it/s]
Fit source/group: 93%|█████████▎| 2554/2759 [00:23<00:02, 93.33it/s]
Fit source/group: 93%|█████████▎| 2568/2759 [00:24<00:01, 103.82it/s]
Fit source/group: 94%|█████████▎| 2581/2759 [00:24<00:01, 109.65it/s]
Fit source/group: 94%|█████████▍| 2594/2759 [00:24<00:01, 113.82it/s]
Fit source/group: 95%|█████████▍| 2614/2759 [00:24<00:01, 126.59it/s]
Fit source/group: 95%|█████████▌| 2634/2759 [00:24<00:00, 145.34it/s]
Fit source/group: 96%|█████████▌| 2650/2759 [00:24<00:00, 141.02it/s]
Fit source/group: 97%|█████████▋| 2668/2759 [00:24<00:00, 142.54it/s]
Fit source/group: 97%|█████████▋| 2687/2759 [00:24<00:00, 145.59it/s]
Fit source/group: 98%|█████████▊| 2708/2759 [00:24<00:00, 147.77it/s]
Fit source/group: 99%|█████████▊| 2723/2759 [00:25<00:00, 105.17it/s]
Fit source/group: 99%|█████████▉| 2736/2759 [00:25<00:00, 109.08it/s]
Fit source/group: 100%|█████████▉| 2757/2759 [00:25<00:00, 131.33it/s]
Fit source/group: 100%|██████████| 2759/2759 [00:25<00:00, 108.38it/s]
WARNING: One or more fit(s) may not have converged. Please check the "flags" column in the output table. [photutils.psf.photometry]
Add model sources: 0%| | 0/2759 [00:00<?, ?it/s]
Add model sources: 21%|██ | 582/2759 [00:00<00:00, 5810.23it/s]
Add model sources: 42%|████▏ | 1164/2759 [00:00<00:00, 5702.94it/s]
Add model sources: 63%|██████▎ | 1735/2759 [00:00<00:00, 5506.93it/s]
Add model sources: 84%|████████▍ | 2323/2759 [00:00<00:00, 5647.78it/s]
Add model sources: 100%|██████████| 2759/2759 [00:00<00:00, 5675.87it/s]
Again, we convert the pixel coordinates to sky coordinates and add them to the catalog.
wcs2 = WCS(hdr2) # NISP
radec = wcs2.all_pix2world(phot2["x_fit"],phot2["y_fit"],0)
phot2["ra_fit"] = radec[0]
phot2["dec_fit"] = radec[1]
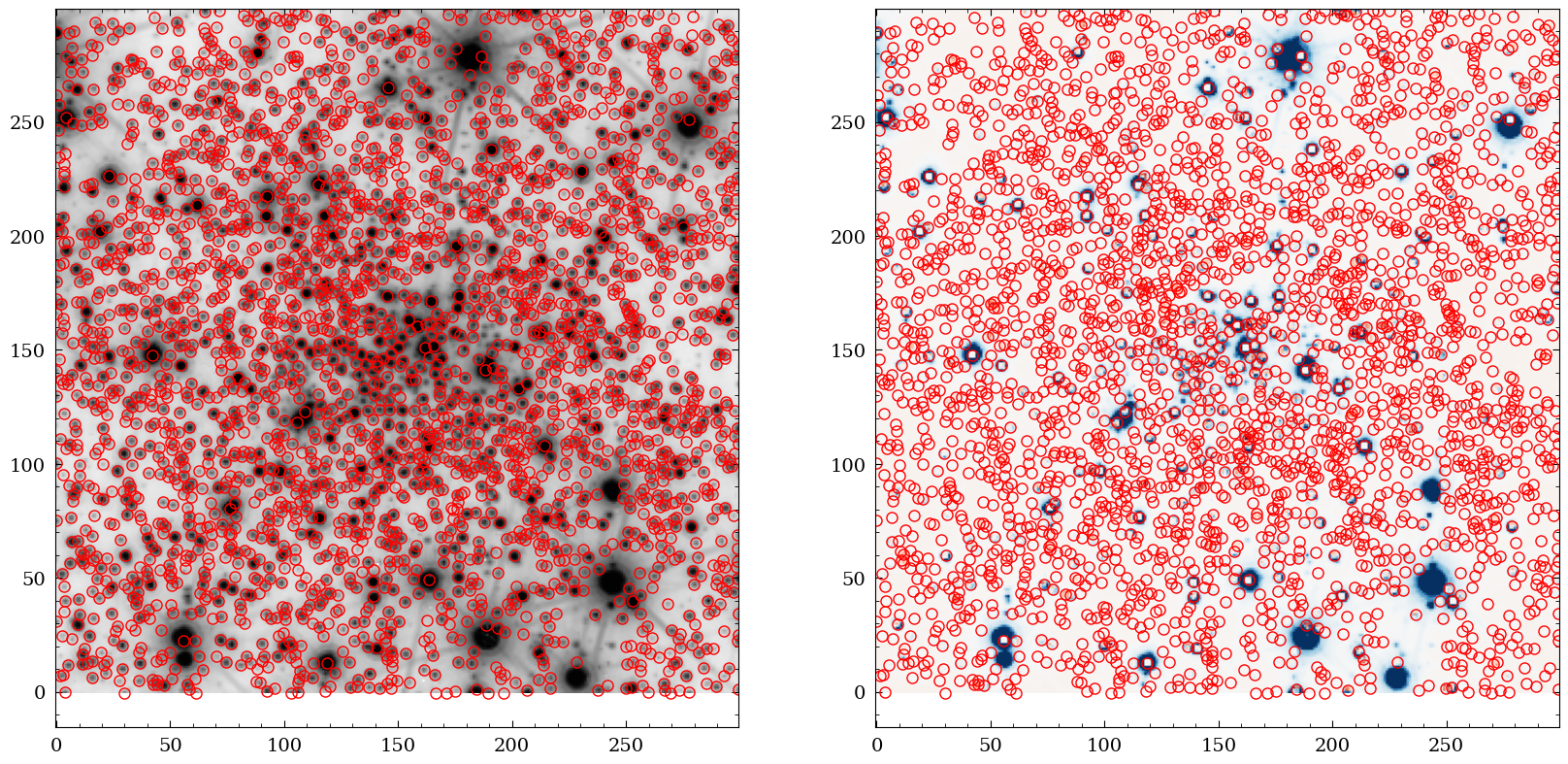
Finally, we create the same figure as above, showing the NISP image and the residual with the (VIS-extracted) sources overlaid.
fig = plt.figure(figsize=(20,10))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.imshow(np.log10(img2), cmap="Greys", origin="lower")
ax1.plot(phot2["x_fit"], phot2["y_fit"] , "o", markersize=8 , markeredgecolor="red", fillstyle="none")
ax2.imshow(resimage2,vmin=-20*std2, vmax=20*std2, cmap="RdBu", origin="lower")
ax2.plot(phot2["x_fit"], phot2["y_fit"] , "o", markersize=8 , markeredgecolor="red", fillstyle="none")
plt.show()
Load Gaia Catalog#
We now load the Gaia sources at the location of the globular clusters. The goal is to compare the photometry of Gaia to the one derived above for the Euclid VIS and NISP images. This is scientifically useful, for example we can compute the colors of the stars in the Gaia optical bands and the Euclid near-IR bands.
To search for Gaia sources, we use astroquery again.
We first have to elimiate the row limit for the Gaia query by setting
Gaia.ROW_LIMIT = -1
Next, we request the Gaia catalog around the position of the globular cluster. We use the same size as the cutout size.
gaia_objects = Gaia.query_object_async(coordinate=coord, radius = cutout_size/2)
print("Number of Gaia stars found: {}".format(len(gaia_objects)))
INFO: Query finished. [astroquery.utils.tap.core]
Number of Gaia stars found: 1202
We then convert the sky coordinates of the Gaia stars to (x,y) image coordinates for VIS and NISP images using the corresponding WCS. This makes it more easy to plot the Gaia sources later on the images.
wcs = WCS(hdr) # VIS
wcs2 = WCS(hdr2) # NISP
xy = wcs.all_world2pix(gaia_objects["ra"],gaia_objects["dec"],0)
xy2 = wcs2.all_world2pix(gaia_objects["ra"],gaia_objects["dec"],0)
gaia_objects["x_vis"] = xy[0]
gaia_objects["y_vis"] = xy[1]
gaia_objects["x_nisp"] = xy2[0]
gaia_objects["y_nisp"] = xy2[1]
We save the Gaia table to disk as we will later use it for the visualization in Firefly.
gaia_objects.write("./data/gaiatable.csv", format="csv", overwrite=True)
Now we can overlay the Gaia sources on the VIS and NISP images (here the x/y coordinates become handy).
fig = plt.figure(figsize=(20,10))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.imshow(np.log10(img), cmap="Greys", origin="lower")
ax1.plot(gaia_objects["x_vis"], gaia_objects["y_vis"] , "o", markersize=8 , markeredgecolor="red", fillstyle="none")
ax1.set_title("VIS")
ax2.imshow(np.log10(img2), cmap="Greys", origin="lower")
ax2.plot(gaia_objects["x_nisp"], gaia_objects["y_nisp"] , "o", markersize=8 , markeredgecolor="red", fillstyle="none")
ax2.set_title("NISP")
plt.show()
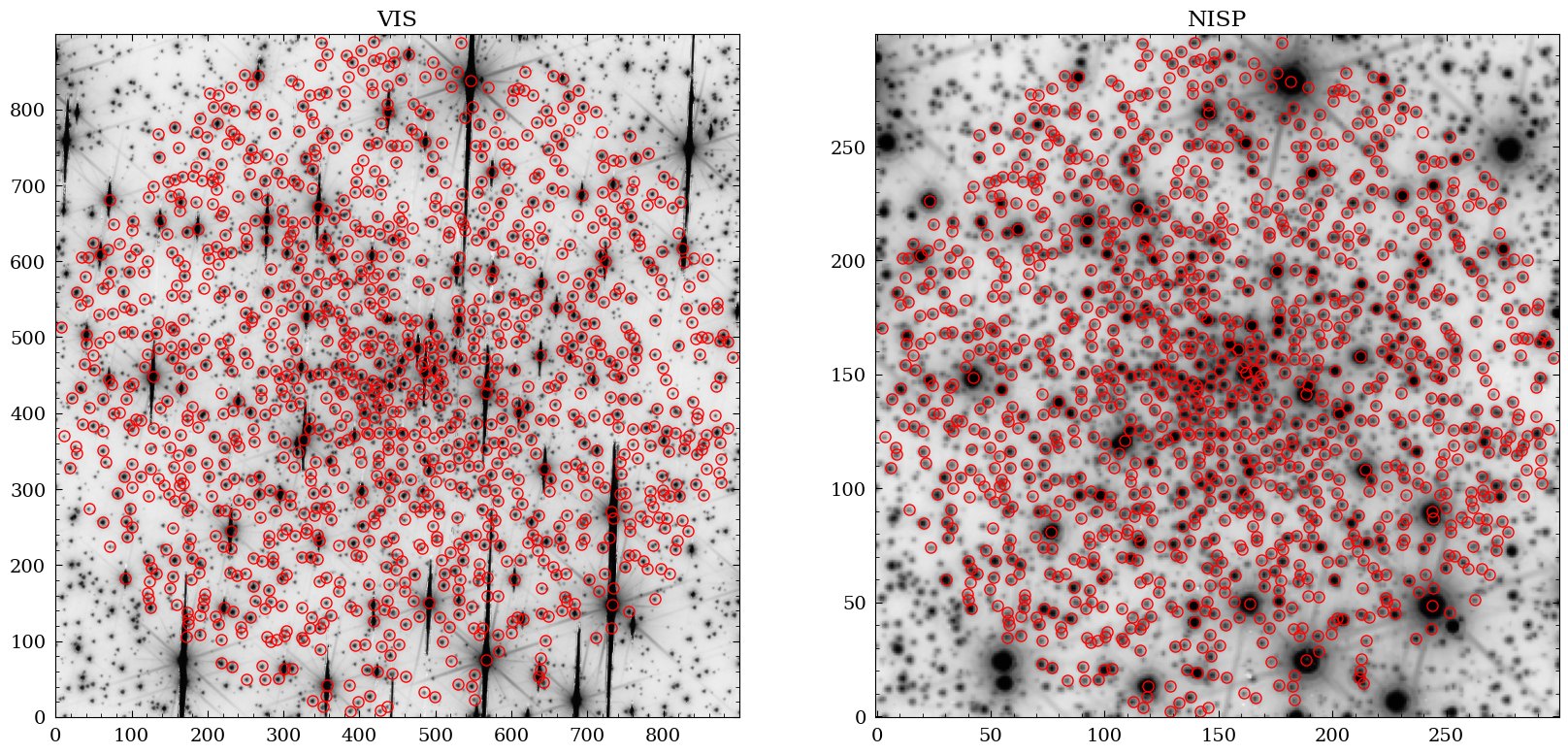
Match the Gaia Catalog to the VIS and NISP Catalogs#
Now, we match the Gaia source positions to the extracted sources in the VIS and NISP images.
We first define which Gaia columns to copy to the matched catalog as well as the matching distance.
gaia_keys = ["source_id", "phot_g_mean_mag", "phot_bp_mean_mag", "phot_rp_mean_mag","ra","dec","pmra","pmdec"]
matching_distance = 0.6*u.arcsecond
First match to the VIS image. We use the astropy SkyCoord() function for matching in sky coordinates.
c = SkyCoord(ra=phot["ra_fit"]*u.degree, dec=phot["dec_fit"]*u.degree )
catalog = SkyCoord(ra=gaia_objects["ra"].data*u.degree, dec=gaia_objects["dec"].data*u.degree)
idx, d2d, d3d = c.match_to_catalog_sky(catalog)
sel_matched = np.where(d2d.to(u.arcsecond) < (matching_distance))[0]
print("Gaia Sources matched to VIS: {}".format( len(sel_matched) ) )
phot["gaia_distance"] = d2d.to(u.arcsecond)
for gaia_key in gaia_keys:
phot["gaia_{}".format(gaia_key)] = 0.0
phot["gaia_{}".format(gaia_key)][sel_matched] = gaia_objects[gaia_key][idx[sel_matched]]
Gaia Sources matched to VIS: 1223
And then we add the NISP sources. Note that we do not have to perform matching here because by design the VIS and NISP sources are matched (spatial prior forced photometry).
phot2["gaia_distance"] = d2d.to(u.arcsecond)
for gaia_key in gaia_keys:
phot2["gaia_{}".format(gaia_key)] = 0.0
phot2["gaia_{}".format(gaia_key)][sel_matched] = gaia_objects[gaia_key][idx[sel_matched]]
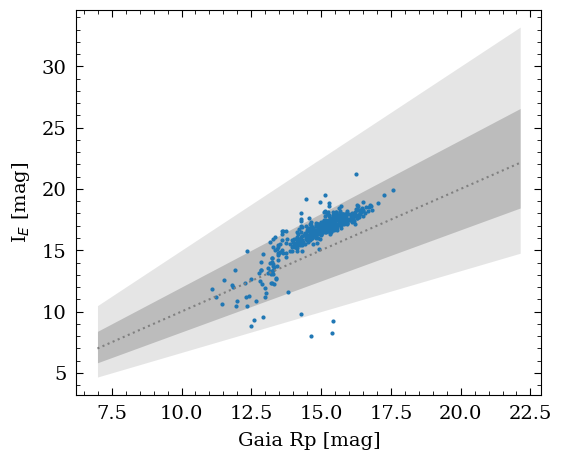
Once matched, we can now compare the Gaia and Euclid/NISP magnitudes of the stars.
# Data
x = phot["gaia_phot_rp_mean_mag"]
y = -2.5*np.log10(phot["flux_fit"]) + hdr["ZP_STACK"]
# selection
sel_good = np.where(phot["gaia_source_id"] > 0)[0]
x = x[sel_good]
y = y[sel_good]
fig = plt.figure(figsize=(6,5))
ax1 = fig.add_subplot(1,1,1)
ax1.plot(x , y , "o", markersize=2)
minlim = np.nanmin(np.concatenate((x,y)))
maxlim = np.nanmax(np.concatenate((x,y)))
ax1.fill_between(np.asarray([minlim,maxlim]),np.asarray([minlim,maxlim])/1.5,np.asarray([minlim,maxlim])*1.5, color="gray", alpha=0.2, linewidth=0)
ax1.fill_between(np.asarray([minlim,maxlim]),np.asarray([minlim,maxlim])/1.2,np.asarray([minlim,maxlim])*1.2, color="gray", alpha=0.4, linewidth=0)
ax1.plot(np.asarray([minlim,maxlim]),np.asarray([minlim,maxlim]), ":", color="gray")
ax1.set_xlabel("Gaia Rp [mag]")
ax1.set_ylabel("I$_E$ [mag]")
plt.show()
Visualization with Firefly#
At the end of this Notebook, we demonstrate how we can visualize the images and catalogs created above in Firefly.
We start by initializing the Firefly client.
The following line will open a new Firefly GUI in a separate tab inside the Jupyter Notebook environment. The user can drag the tab onto the currently open tab to create a “split tab”. This the user to see the code and images side-by-side.
# Uncomment when using within Jupyter Lab with jupyter_firefly_extensions installed
# fc = FireflyClient.make_lab_client()
# Uncomment for contexts other than the above
fc = FireflyClient.make_client(url="https://irsa.ipac.caltech.edu/irsaviewer")
In order to display in image or catalog in Firefly, it needs to be uploaded to the Firefly server. We do this here using the upload_file() function.
We first upload the FITS image that we created above.
fval = fc.upload_file('./data/euclid_images_test.fits')
Once the image is uploaded we can use the show_fits() function to display it.
Note that our FITS image has multiple extensions (VIS, and NISP bands). We can open them separately in new Firefly tabs by looping over the HDUs and specifying the plot ID by the extension’s name.
for hh,hdu in enumerate(hdulcutout):
fc.show_fits(fval, MultiImageIdx=hh, plot_id=hdu.header["EXTNAME"] )
We can lock the WCS between the images (allowing the user to pan and zoom the images simultaneously) by running:
fc.align_images(lock_match=True)
{'success': True}
In the same way, we can upload a table, in this case our Gaia table. We again use upload_file() but in this case we use show_table() to show it in Firefly.
tval = fc.upload_file('./data/gaiatable.csv')
fc.show_table(tval, tbl_id = "gaiatable")
{'success': True}
Now, check out the Firefly GUI. You can zoom the images, click on sources, filter the table, display different selection, and much more!
About this Notebook#
Author: Andreas Faisst (IPAC Scientist)
Updated: 2025-03-17
Contact: the IRSA Helpdesk with questions or reporting problems.